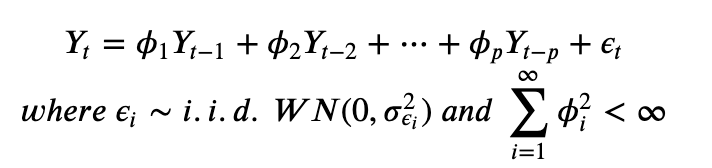1. ARIMA 분석 ARMA분석은 데이터에 추세가 있고 이 추세를 없애기 위해 ARMA에 (추세)차분을 추가로 적용한 상태를 말한다. (ARIMA = ARMA+차분) 즉 ARIMA(p,d,q)모델은 Y_t대신 (1-L)^d*Y_t 가 대입된 형태이다. acf결과 추세로 인한 비정상성이 보이고, 차분의 필요성이 있을 때 ARIMA(차분+ARMA적합) 분석을 수행한다. 2. 모수추정 ARMA와 마찬가지로 ACF와 PACF그래프를 보고 모수를 추정한다. 대략 아래와 같다. 3. 코드 import numpy as np import statsmodels.api as sm import matplotlib.pyplot as plt # 2차누적/1차누적/미누적 데이터생성 및 적분차수 이해 np.random.seed(..