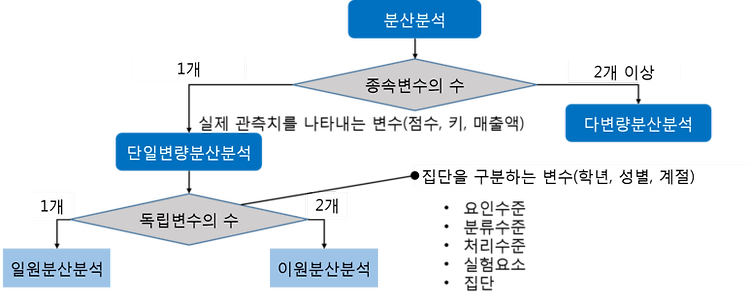
1. t-검정 (1) 일표본 t-검정 정의 : 단일모집단에서 관심이 있는 연속형 변수의 평균값을 특정 기준값과 비교하고자 할 때 사용 ex) 과수원에서 생산되는 사과의 평균 무게가 200g이라고 할 때, 실제로 과수원에서 생산되는 전체 사과의 평균 무게가 200g인지 알고 싶은 경우 수행 - 정규분포를 따라야함 (2) 대응표본 t-검정 정의: 단일모집단에 대해 두번의 처리를 가했을 때, 두 개의 처리에 따른 평균의 차이를 비교하고자 할 때. ex) 수면영양제 복용효과를 조사하기 위해 영양제 복용 전과 후의 평균 수면시간에 차이가 있는지 비교. - 정규분포를 따라야함 (3) 독립표본 t-검정 정의 : 두개의 독립된 모집단의 평균을 비교 ex) 성별에 따른 출근시간에 차이를 확인. (독립변수:성별, ..