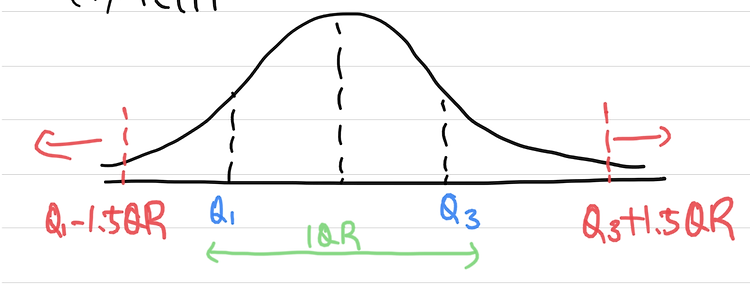
데이터 시각화 1. 같은범주에 많은 양의 데이터에 의미 부여하여 효율적으로 전달 2. 데이터의 시각적 표현의 연구 3. 속성이나 변수를 가진 단위를 포함한 정보 4. 명확하고 정확하게 커뮤니케이션 하기위한 목적 5. 마인드맵, 의사결정트리, 통계그래픽 정보 시각화 1. 큰 범주에 해당하는 정보를 시각화 2. 대규모 비수량 정보를 시각화 3. 트리맵, 분기도, 수지도, 히트맵 정보시각화 (인포그래픽) 1. 사람이 사용할 수 있는 효과적인 정보와 복잡하고 구조적이지 않은 기술데이터를 시각적으로 표현하는 방법 2. 인지(의미만들기) + 지각(형태만들기) + 경험(맥락만들기) 3. 인포그래픽 : 중요한 정보를 한장의 그래픽으로 표현해 이를 보는 사람들이 손쉽게 해당 정보를 이해할 수 있도록 만든 그래픽 ..