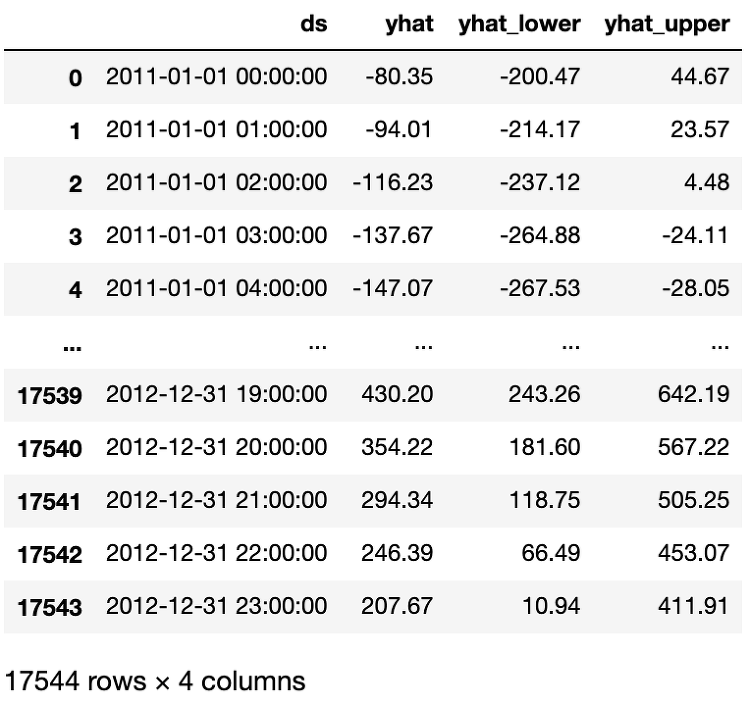
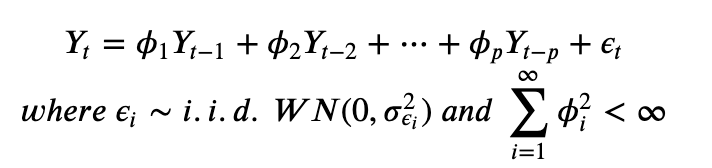cross_validation from fbprophet.diagnostics import cross_validation import fbprophet as Prophet model = Prophet.Prophet().fit(data) df_cv = cross_validation(model, initial='730 days', period='180 days',horizon = '365 days') 모델을 학습한 후 cross_validation으로 체크한다. 이때 parameter값들 initial, peroid, horizion의 의미를 정리한다. 공식문서 다음과 같이 정의 되어있다. This cross validation procedure can be done automatically for a ra..