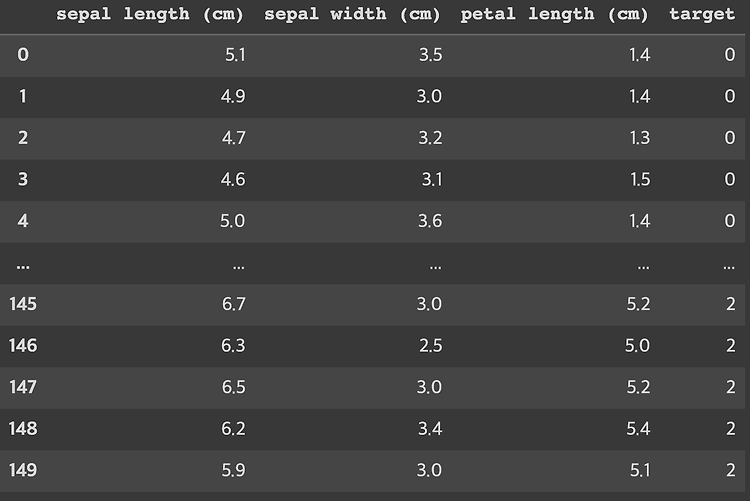
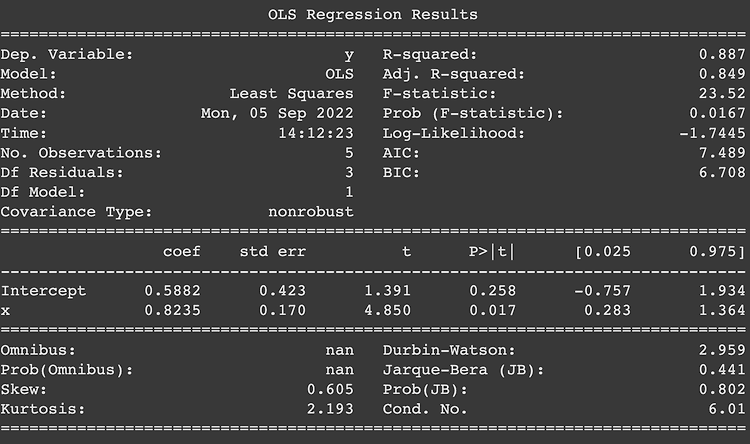
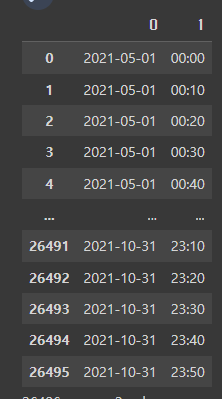
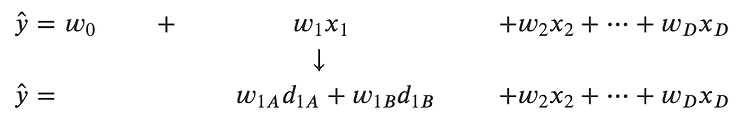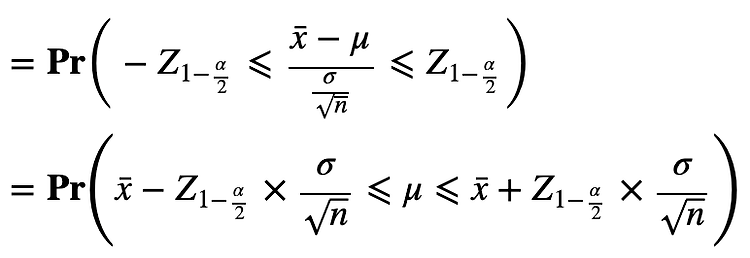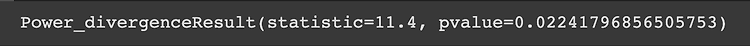groupby [] 사용 df.groupby(["a","b"])["a"].count() => a를 기준으로 b의 도메인별 개수를 보여준다 (example 1) df.groupby(['Survived','Pclass'])['Survived'].count() Survived Pclass 0 1 80 2 97 3 372 1 1 136 2 87 3 119 Name: Survived, dtype: int64 (example 2) df.groupby(['Pclass','Survived'])['Survived'].count() Pclass Survived 1 0 80 1 136 2 0 97 1 87 3 0 372 1 119 Name: Survived, dtype: int64 groupby agg 사용 df.group..