
반응형
스케일링은 컬럼별 단위차이를 줄여서 연산속도를 빠르게 하고 조건수를 줄여서 최적화 성능을 향상시킨다.
standard scaler
평균을 빼고 표준편차로 나누는 변환.
각 변수가 정규분포를 따른다는 가정 후 수행하므로 정규분포가 아닐 시 최선이 아닐 수 있다.
(1) 식

(2) 그래프

min-max scaling
가장 많이 사용되는 알고리즘, 값을 0~1로 바꿔줌.
각 변수가 정규분포가 아니거나 표준편차가 매우 작을 때 효과적이다.
(1) 식

(2) 그래프

robust scaling
최소-최대 스케일과 유사하다. 최소최대 대신 IQR(InterQuartile Range)중 1분위수, 3분위수를 사용한다.
이상치의 영향을 최소화 하였기 떄문에 이상치가 있는 데이터에 효과적이다.
(1) 식
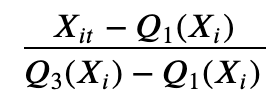
(2) 그래프

normalizer scaling
각 변수를 전체 n개의 변수들의 크기로 나눈다.
각 변수들의 값을 원점으로 부터 1만큼 떨어져 있는 범위 내로 변환.
(1) 식

(2) 그래프

정규화 및 역규화 코드
(1) 기본 순서
from sklearn import preprocessing
# preprocessing.MinMaxScaler()
# preprocessing.StandardScaler()
# preprocessing.RobustScaler()
# preprocessing.Normalizer()
# 1. 스케일러를 선택 후 스케일러 객체를 지정한다
scaler = preprocessing.MinMaxScaler()
# 2. 스케일러 객체의 fit()함수를 이용하여 필요한 파라미터를 저장한다
# scaler_fit에는 칼럼별 최대와 최소값이 저장되어있다.
scaler_fit = scaler.fit(X)
# 3. 스케일러 객체의 transform()함수를 이용하여 스케일링을 수행한다
result=scaler_fit.transform(X)
* 역정규화
inverse_scaled_data = scaler.inverse_transform(scaled_data)
(2) 함수화
def feature_engineering_scaling(scaler, X_train, X_test):
# scaler파라미터는 아래 4개중 하나를 넣는다
# preprocessing.MinMaxScaler()
# preprocessing.StandardScaler()
# preprocessing.RobustScaler()
# preprocessing.Normalizer()
scaler = scaler
scaler_fit = scaler.fit(X_train)
X_train_scaling = pd.DataFrame(scaler_fit.transform(X_train),
index=X_train.index, columns=X_train.columns)
X_test_scaling = pd.DataFrame(scaler_fit.transform(X_test),
index=X_test.index, columns=X_test.columns)
return X_train_scaling, X_test_scaling
* 출처 : 패스트캠퍼스 파이썬을 활용한 시계열 데이터분석 A-Z
반응형