
반응형
독립변수간에 상관성이 있으면 과적합되거나 정확한 분석이 되지 않을 수 있다. 따라서 변수들간에 상관성을 확인하고 상관이 있는 변수들은 제거한다.
변수를 제거하는 방법은 VIF, PCA 2가지가 있다. 상황에 따라 적절하게 사용하면 된다.
참고로 PCA는 존재하는 변수 중 일부를 선택하거나 제거하는 것이 아니라 새로운 차원을 만들기 때문에 수행 후 설명성이 부족하다.
이 장에서는 VIF(Variance Inflation Factor)에 대해서 알아 본다.
0. VIF
독립변수를 다른 독립변수들로 선형회귀한 성능을 나타내며 가장 상호의존적인 독립변수를 제거한다.
의존성이 낮은(분산이 작은) 독립변수를 선택하거나, 의존성이 높은(분산이 높은) 독립변수를 제거하며 사용한다
1. 식
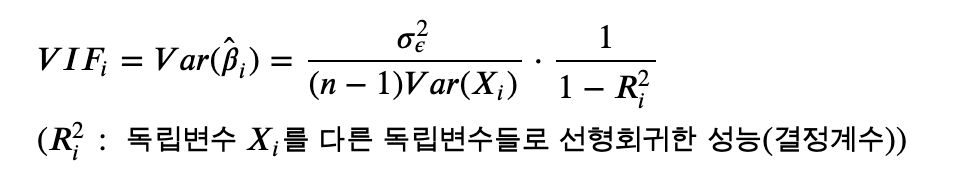
2. 코드
<example>
X_train_feRS.columns
참고로 독립변수들간의 상관관계가 있는지 분석전에 예측해보는 방법은 corr()함수를 사용하여 시각화 해보는 것이다.
# correlation from features
raw_feRS.corr().loc[X_colname, X_colname].style.background_gradient().set_precision(2).set_properties(**{'font-size': '11pt'})
위에서 count_trend, temp, atemp같은 변수들이 다른 변수들과의 상관계수가 높은것을 알 수 있다. 즉 이러한 변수들은 vif값이 높이 나올 것으로 예상할 수 있는 것이다.
# extract effective features using variance inflation factor
vif = pd.DataFrame()
# variance_inflation_factor(X, i) : Xi를 x나머지로 회귀분석한 후 VIF값을 구한것. 즉 xi의 vif값. 즉 이값이 높을수록 종속성이 높다는 뜻
vif['VIF_Factor'] = [variance_inflation_factor(X_train_feRS.values, i)
for i in range(X_train_feRS.shape[1])]
vif['Feature'] = X_train_feRS.columns
vif.sort_values(by='VIF_Factor', ascending=True)

- 함수화
### Functionalize
# num_variables : 상위 몇개까지 쓸것인지에 관한 하이퍼파라미터
# 다중공선성이 높은 변수들이 제거된 후 사용할 변수가 리턴된다.
def feature_engineering_XbyVIF(X_train, num_variables):
vif = pd.DataFrame()
vif['VIF_Factor'] = [variance_inflation_factor(X_train.values, i)
for i in range(X_train.shape[1])]
vif['Feature'] = X_train.columns
X_colname_vif = vif.sort_values(by='VIF_Factor', ascending=True)['Feature'][:num_variables].values
return X_colname_vif
* 코드출처 : 패스트캠퍼스 파이썬을 활용한 시계열 데이터분석 A-Z
반응형