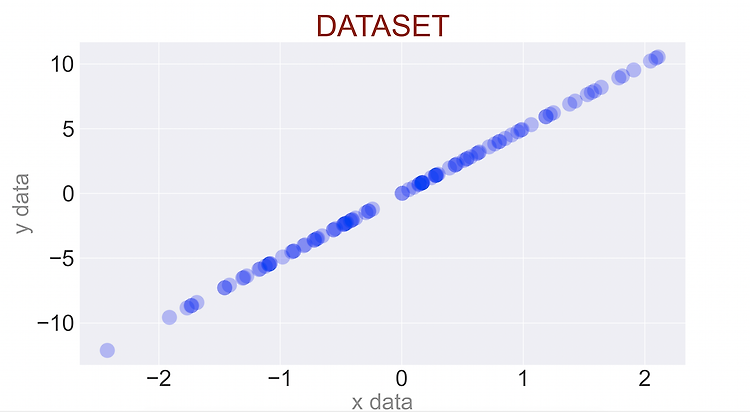
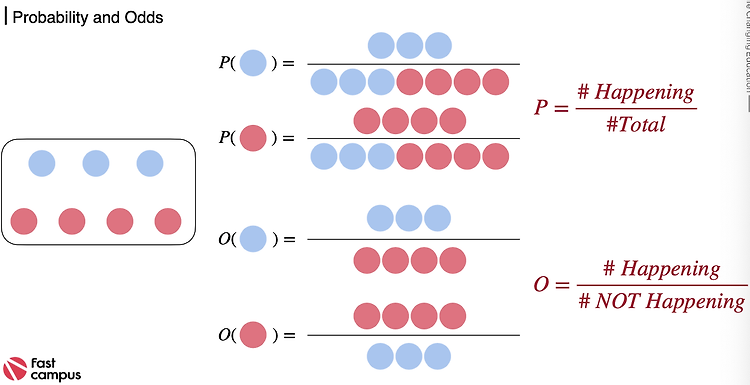
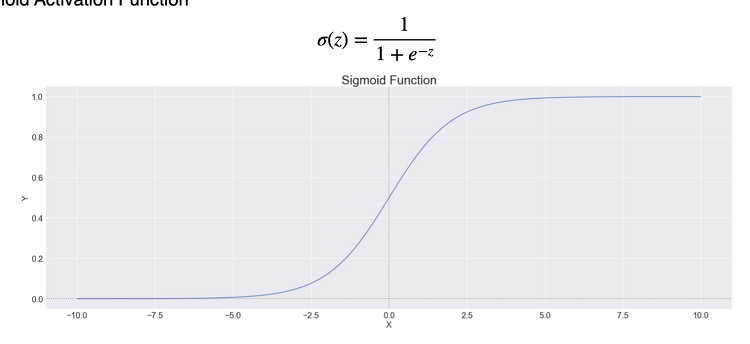
로지스틱회귀 데이터 만들기
로지스틱회귀를 위한 범주형 데이터를 만드는 방법import numpy as npx_dict={'mean':1, 'std':1, 'n_sample':300, 'noise_factor':0.3,'cutoff':1, 'direction':1}def dataset_generator(x_dict): x_data=np.random.normal(x_dict['mean'], x_dict['std'], x_dict['n_sample']) #np.random.normal(평균,표준편차,갯수) : 평균과 표준편차에 맞는 데이터를 갯수만큼 랜덤으로 만든다 x_data_noise=x_data+x_dict['noise_factor']*np.random.normal(0,1,x_dict['n_sample']) # 반..