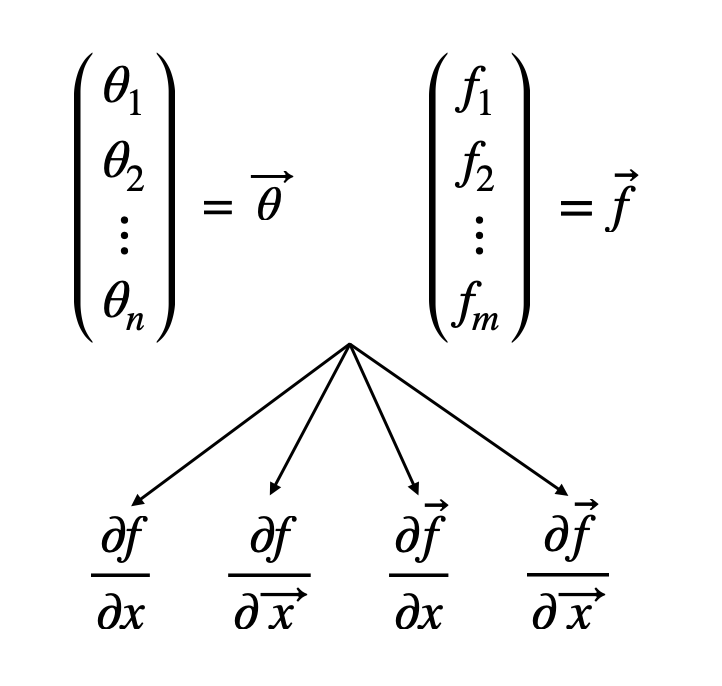
회귀분석 #사이킷런#넘파이#numpy#scikit-learn
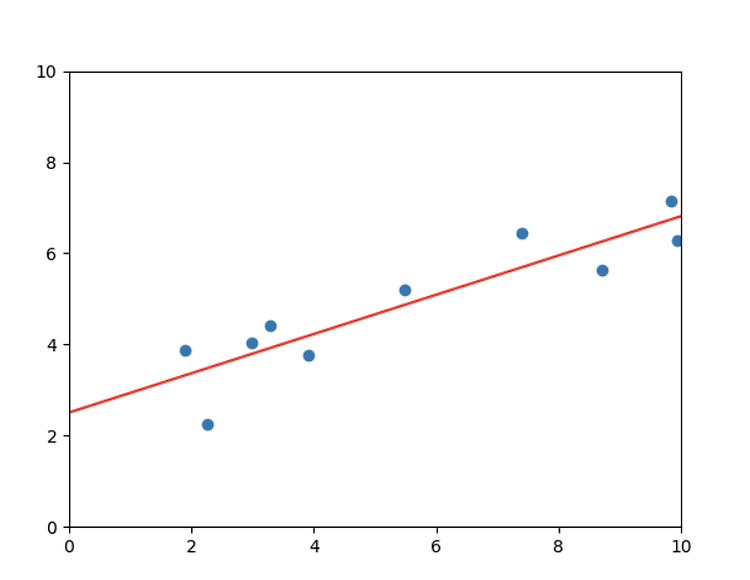
1. 점찍기 x,y점들을 matplot라이브러리를 이용하여 점찍기 # [점그리기] import matplotlib.pyplot as plt import numpy as np # 1. x,y값 X = [8.70153760, 3.90825773, 1.89362433, 3.28730045, 7.39333004, 2.98984649, 2.25757240, 9.84450732, 9.94589513, 5.48321616] Y = [5.64413093, 3.75876583, 3.87233310, 4.40990425, 6.43845020, 4.02827829, 2.26105955, 7.15768995, 6.29097441, 5.19692852] plt.scatter(X, Y) # (x, y) 점그리기 plt.show(..