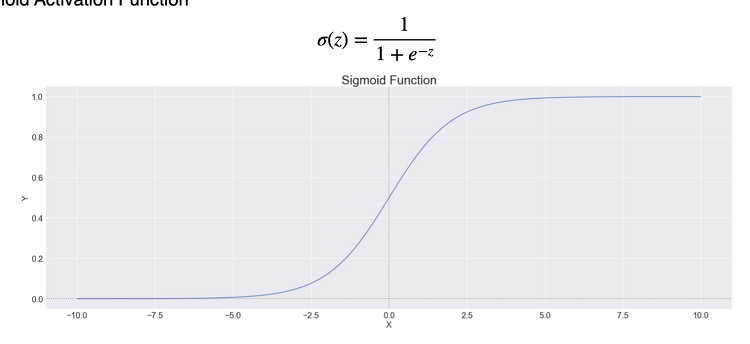
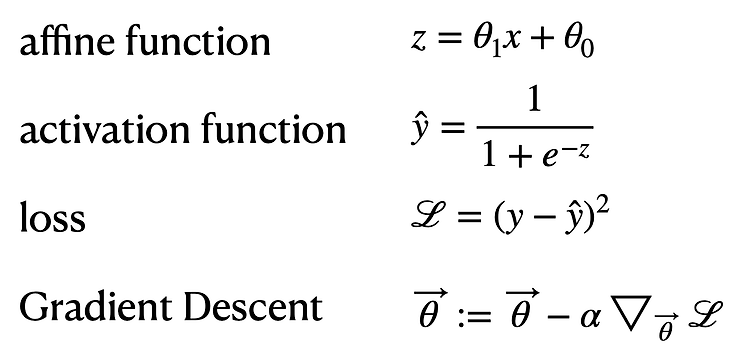0. 서론 sigmoid와 tanh에서 왜 gradient vanishing문제가 발생하는지 알아보고, 이를 어떻게 relu를 이용해서 해결할 수 있는지 알아본다. 1. tanh와 simoid의 기울기 tanh와 sigmoid의 도함수는 위사진과 같다. 딥러닝은 back propagation 과정에서 활성함수의 기울기만큼 웨이트가 개선된다. 그런데 기울기의 최대가 tanh의 경우 x=0에서 1, sigmoid는 x=0에서 0.3정도 된다. 즉 tanh나 sigmoid를 사용하면 대부분의 경우 활성함수의 기울기가 1보다 작다. 이때 딥러닝 모델의 layer가 많다면, back propagation과정에서 1보다 작은값이 계속해서 곱해지게 된다. 이러면 기울기가 무한히 작아지는 현상이 발생하며 이 현상을 g..