
반응형
위키독스 교재에 있는 주제추출 알고리즘 LSA실습을 진행해본다
1. 데이터 추출
뉴스기사 11314건을 사용한다.
(1) 필요한 라이브러리 다운
import pandas as pd
from sklearn.datasets import fetch_20newsgroups
dataset = fetch_20newsgroups(shuffle=True, random_state=1, remove=('headers', 'footers', 'quotes'))
documents = dataset.data
len(documents)11314
(2) 데이터 형태 확인
documents[1]
(3) 카테고리확인
총 20개의 토픽이 있다.
print(dataset.target_names)
(4) 전처리
# 텍스트 전처리
news_df = pd.DataFrame({'document':documents})
# 특수 문자 제거
news_df['clean_doc'] = news_df['document'].str.replace("[^a-zA-Z]", " ")
# 길이가 3이하인 단어는 제거 (길이가 짧은 단어 제거)
news_df['clean_doc'] = news_df['clean_doc'].apply(lambda x: ' '.join([w for w in x.split() if len(w)>3]))
# 전체 단어에 대한 소문자 변환
news_df['clean_doc'] = news_df['clean_doc'].apply(lambda x: x.lower())news_df['clean_doc'][1]
(5) 토큰화
tokenized_doc = news_df['clean_doc'].apply(lambda x: x.split()) # 토큰화
(6) 전처리된 데이터
# 뉴스 총 11314개를 tokenize한 데이터
print(len(tokenized_doc))
#데이터확인
tokenized_doc[:5]
2. 코퍼스 만들기
(1) 단어를 id로 바꾸고 뜻을 dictionary로 만들기
from gensim import corpora
# 각 단어를 (단어id, 나온횟수) 로 바꾸는 작업
dictionary = corpora.Dictionary(tokenized_doc)
corpus = [dictionary.doc2bow(text) for text in tokenized_doc]
(2) 코퍼스와 딕셔너리 확인
# corpus[i] : i번째 뉴스에서 나온단어들을 가지고 (단어id, 나온횟수)들을 저장한 list
print(corpus[1])
# dictionary[j] : id값을 j를 가진 단어가 무엇인지 확인
print(dictionary[66])
3. LDA 모델 훈련시키기
(1) 훈련
import gensim
#20개의 토픽, k=20
NUM_TOPICS = 20
# passes : 알고리즘 동작횟수, num_words : 각 토픽별 출력할 단어
ldamodel = gensim.models.ldamodel.LdaModel(corpus, num_topics = NUM_TOPICS, id2word=dictionary, passes=15)
topics = ldamodel.print_topics(num_words=4)
for topic in topics:
print(topic)(0, '0.012*"government" + 0.009*"president" + 0.009*"with" + 0.008*"that"')
(1, '0.016*"play" + 0.015*"game" + 0.014*"hockey" + 0.014*"period"')
(2, '0.046*"chip" + 0.039*"encryption" + 0.035*"keys" + 0.033*"clipper"')
(3, '0.049*"that" + 0.018*"this" + 0.016*"have" + 0.012*"they"')
(4, '0.034*"armenian" + 0.028*"turkish" + 0.026*"armenians" + 0.024*"were"')
(5, '0.017*"cover" + 0.015*"each" + 0.012*"copies" + 0.008*"appears"')
(6, '0.022*"wiring" + 0.014*"terminals" + 0.010*"wires" + 0.008*"pointer"')
(7, '0.061*"they" + 0.034*"were" + 0.025*"that" + 0.019*"there"')
(8, '0.013*"from" + 0.012*"april" + 0.012*"university" + 0.007*"york"')
(9, '0.023*"that" + 0.013*"have" + 0.013*"with" + 0.012*"this"')
(10, '0.024*"that" + 0.021*"have" + 0.019*"with" + 0.019*"this"')
(11, '0.014*"will" + 0.012*"from" + 0.011*"information" + 0.009*"this"')
(12, '0.008*"nist" + 0.008*"widgets" + 0.007*"byte" + 0.007*"mask"')
(13, '0.022*"file" + 0.014*"windows" + 0.013*"this" + 0.013*"program"')
(14, '0.083*"space" + 0.031*"nasa" + 0.017*"launch" + 0.015*"satellite"')
(15, '0.034*"sale" + 0.032*"price" + 0.029*"shipping" + 0.027*"offer"')
(16, '0.037*"drive" + 0.029*"card" + 0.024*"disk" + 0.024*"with"')
(17, '0.019*"radar" + 0.017*"navy" + 0.015*"smokeless" + 0.012*"detector"')
(18, '0.033*"health" + 0.031*"medical" + 0.022*"disease" + 0.018*"patients"')
(19, '0.034*"water" + 0.033*"wire" + 0.033*"ground" + 0.018*"neutral"')
(2) 토픽별 10개 표시
# 각 토픽별 10개의 단어를 단어를 출력 (위 코드에서 num_words=10을 한것)
for i in range(20):
print(ldamodel.print_topics()[i])(0, '0.012*"government" + 0.009*"president" + 0.009*"with" + 0.008*"that" + 0.007*"were" + 0.007*"states" + 0.007*"state" + 0.007*"from" + 0.006*"this" + 0.005*"guns"')
(1, '0.016*"play" + 0.015*"game" + 0.014*"hockey" + 0.014*"period" + 0.014*"team" + 0.012*"games" + 0.011*"season" + 0.010*"pittsburgh" + 0.008*"power" + 0.008*"detroit"')
(2, '0.046*"chip" + 0.039*"encryption" + 0.035*"keys" + 0.033*"clipper" + 0.019*"algorithm" + 0.016*"escrow" + 0.014*"government" + 0.013*"secure" + 0.012*"encrypted" + 0.012*"bits"')
(3, '0.049*"that" + 0.018*"this" + 0.016*"have" + 0.012*"they" + 0.011*"with" + 0.011*"what" + 0.009*"people" + 0.009*"would" + 0.008*"there" + 0.008*"about"')
(4, '0.034*"armenian" + 0.028*"turkish" + 0.026*"armenians" + 0.024*"were" + 0.022*"their" + 0.021*"jews" + 0.018*"turkey" + 0.015*"greek" + 0.014*"armenia" + 0.013*"turks"')
(5, '0.017*"cover" + 0.015*"each" + 0.012*"copies" + 0.008*"appears" + 0.008*"annual" + 0.007*"hulk" + 0.007*"ghost" + 0.007*"issue" + 0.007*"part" + 0.007*"runner"')
(6, '0.022*"wiring" + 0.014*"terminals" + 0.010*"wires" + 0.008*"pointer" + 0.007*"breaker" + 0.007*"wanna" + 0.006*"volts" + 0.006*"rayshade" + 0.006*"forty" + 0.006*"boom"')
(7, '0.061*"they" + 0.034*"were" + 0.025*"that" + 0.019*"there" + 0.017*"said" + 0.016*"them" + 0.013*"when" + 0.012*"didn" + 0.012*"went" + 0.010*"what"')
(8, '0.013*"from" + 0.012*"april" + 0.012*"university" + 0.007*"york" + 0.007*"washington" + 0.006*"world" + 0.006*"center" + 0.005*"german" + 0.005*"germany" + 0.005*"national"')
(9, '0.023*"that" + 0.013*"have" + 0.013*"with" + 0.012*"this" + 0.012*"they" + 0.009*"year" + 0.009*"will" + 0.007*"would" + 0.007*"good" + 0.007*"just"')
(10, '0.024*"that" + 0.021*"have" + 0.019*"with" + 0.019*"this" + 0.009*"there" + 0.009*"would" + 0.008*"about" + 0.008*"some" + 0.008*"from" + 0.008*"like"')
(11, '0.014*"will" + 0.012*"from" + 0.011*"information" + 0.009*"this" + 0.008*"available" + 0.008*"data" + 0.007*"with" + 0.007*"mail" + 0.006*"system" + 0.006*"public"')
(12, '0.008*"nist" + 0.008*"widgets" + 0.007*"byte" + 0.007*"mask" + 0.007*"intel" + 0.006*"ncsl" + 0.006*"stealth" + 0.006*"math" + 0.005*"andrew" + 0.005*"expose"')
(13, '0.022*"file" + 0.014*"windows" + 0.013*"this" + 0.013*"program" + 0.011*"from" + 0.010*"files" + 0.010*"window" + 0.010*"your" + 0.009*"output" + 0.009*"that"')
(14, '0.083*"space" + 0.031*"nasa" + 0.017*"launch" + 0.015*"satellite" + 0.014*"earth" + 0.013*"shuttle" + 0.012*"orbit" + 0.011*"lunar" + 0.011*"moon" + 0.010*"flight"')
(15, '0.034*"sale" + 0.032*"price" + 0.029*"shipping" + 0.027*"offer" + 0.024*"condition" + 0.020*"asking" + 0.018*"sell" + 0.018*"please" + 0.015*"email" + 0.014*"interested"')
(16, '0.037*"drive" + 0.029*"card" + 0.024*"disk" + 0.024*"with" + 0.023*"scsi" + 0.015*"system" + 0.014*"memory" + 0.014*"hard" + 0.014*"video" + 0.012*"drives"')
(17, '0.019*"radar" + 0.017*"navy" + 0.015*"smokeless" + 0.012*"detector" + 0.008*"mydisplay" + 0.007*"detectors" + 0.006*"bloody" + 0.006*"technician" + 0.005*"reality" + 0.005*"virtual"')
(18, '0.033*"health" + 0.031*"medical" + 0.022*"disease" + 0.018*"patients" + 0.014*"food" + 0.013*"gordon" + 0.013*"medicine" + 0.012*"pitt" + 0.012*"doctor" + 0.012*"cancer"')
(19, '0.034*"water" + 0.033*"wire" + 0.033*"ground" + 0.018*"neutral" + 0.017*"panel" + 0.010*"connected" + 0.009*"circuit" + 0.009*"planes" + 0.009*"exhaust" + 0.008*"aluminum"')
4. 시각화하기
import pyLDAvis.gensim
pyLDAvis.enable_notebook()
vis = pyLDAvis.gensim.prepare(ldamodel, corpus, dictionary)
pyLDAvis.display(vis)[액티브하게 작동한다]
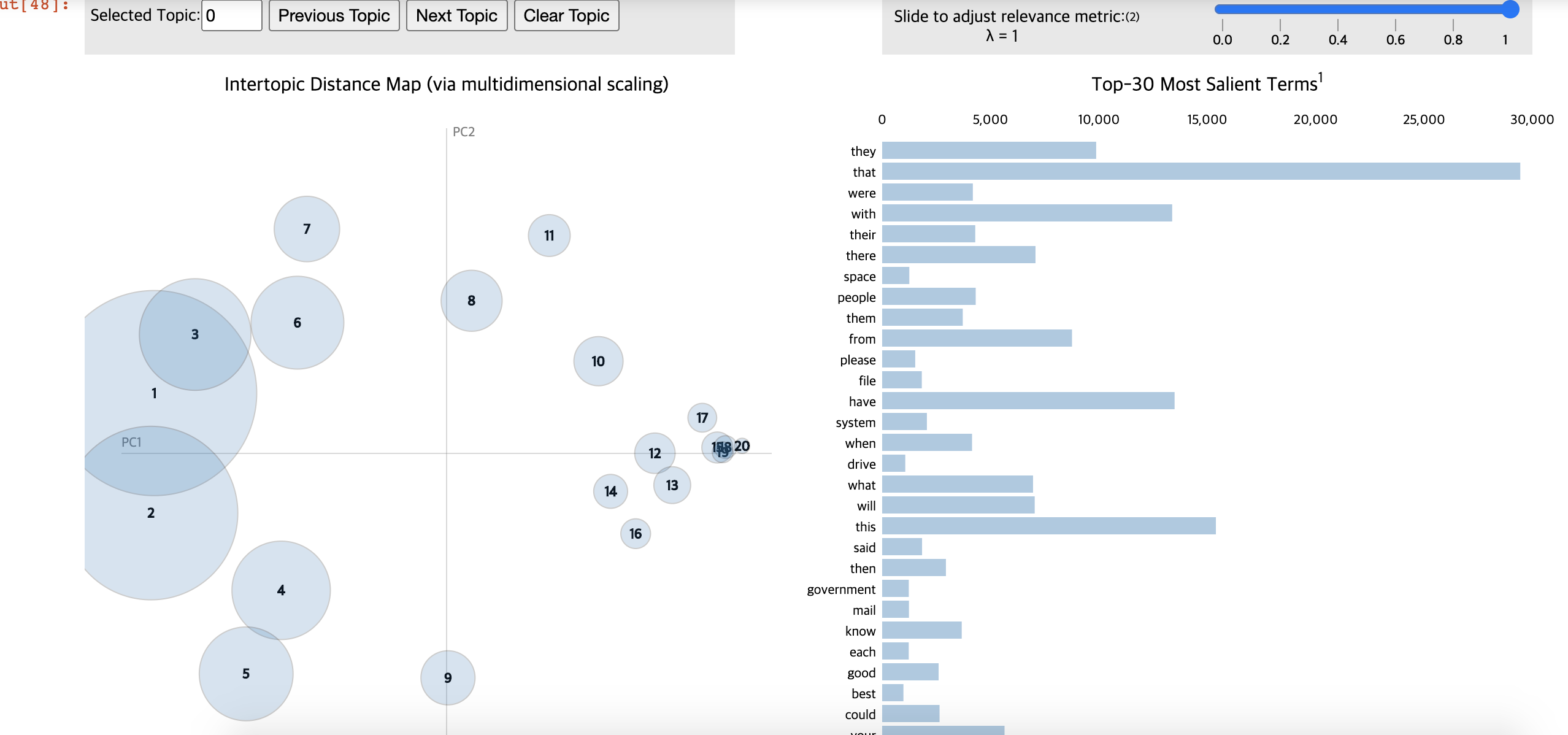
5. 문서별 토픽 분포 보기
(1) 문서별 토픽 분류결과
for i, topic_list in enumerate(ldamodel[corpus]):
if i==5:
break
print(i,'번째 문서의 topic 비율은',topic_list)0 번째 문서의 topic 비율은 [(3, 0.6047512), (4, 0.05386149), (8, 0.06141739), (10, 0.27063268)]
1 번째 문서의 topic 비율은 [(3, 0.6542798), (9, 0.18028764), (13, 0.12686847), (19, 0.021867014)]
2 번째 문서의 topic 비율은 [(3, 0.794237), (9, 0.11266169), (10, 0.082437746)]
3 번째 문서의 topic 비율은 [(2, 0.08471892), (3, 0.31199822), (4, 0.01452577), (9, 0.07719256), (10, 0.38351992), (11, 0.09574509), (14, 0.02489177)]
4 번째 문서의 topic 비율은 [(1, 0.18266954), (3, 0.060955822), (8, 0.21825173), (9, 0.42798224), (13, 0.08669385)]
(2) 결과를 보기쉽게 처리해주는 함수
def make_topictable_per_doc(ldamodel, corpus):
topic_table = pd.DataFrame()
# 몇 번째 문서인지를 의미하는 문서 번호와 해당 문서의 토픽 비중을 한 줄씩 꺼내온다.
for i, topic_list in enumerate(ldamodel[corpus]):
doc = topic_list[0] if ldamodel.per_word_topics else topic_list
doc = sorted(doc, key=lambda x: (x[1]), reverse=True)
# 각 문서에 대해서 비중이 높은 토픽순으로 토픽을 정렬한다.
# EX) 정렬 전 0번 문서 : (2번 토픽, 48.5%), (8번 토픽, 25%), (10번 토픽, 5%), (12번 토픽, 21.5%),
# Ex) 정렬 후 0번 문서 : (2번 토픽, 48.5%), (8번 토픽, 25%), (12번 토픽, 21.5%), (10번 토픽, 5%)
# 48 > 25 > 21 > 5 순으로 정렬이 된 것.
# 모든 문서에 대해서 각각 아래를 수행
for j, (topic_num, prop_topic) in enumerate(doc): # 몇 번 토픽인지와 비중을 나눠서 저장한다.
if j == 0: # 정렬을 한 상태이므로 가장 앞에 있는 것이 가장 비중이 높은 토픽
topic_table = topic_table.append(pd.Series([int(topic_num), round(prop_topic,4), topic_list]), ignore_index=True)
# 가장 비중이 높은 토픽과, 가장 비중이 높은 토픽의 비중과, 전체 토픽의 비중을 저장한다.
else:
break
return(topic_table)topictable = make_topictable_per_doc(ldamodel, corpus)
topictable = topictable.reset_index() # 문서 번호을 의미하는 열(column)로 사용하기 위해서 인덱스 열을 하나 더 만든다.
topictable.columns = ['문서 번호', '가장 비중이 높은 토픽', '가장 높은 토픽의 비중', '각 토픽의 비중']
topictable[:10]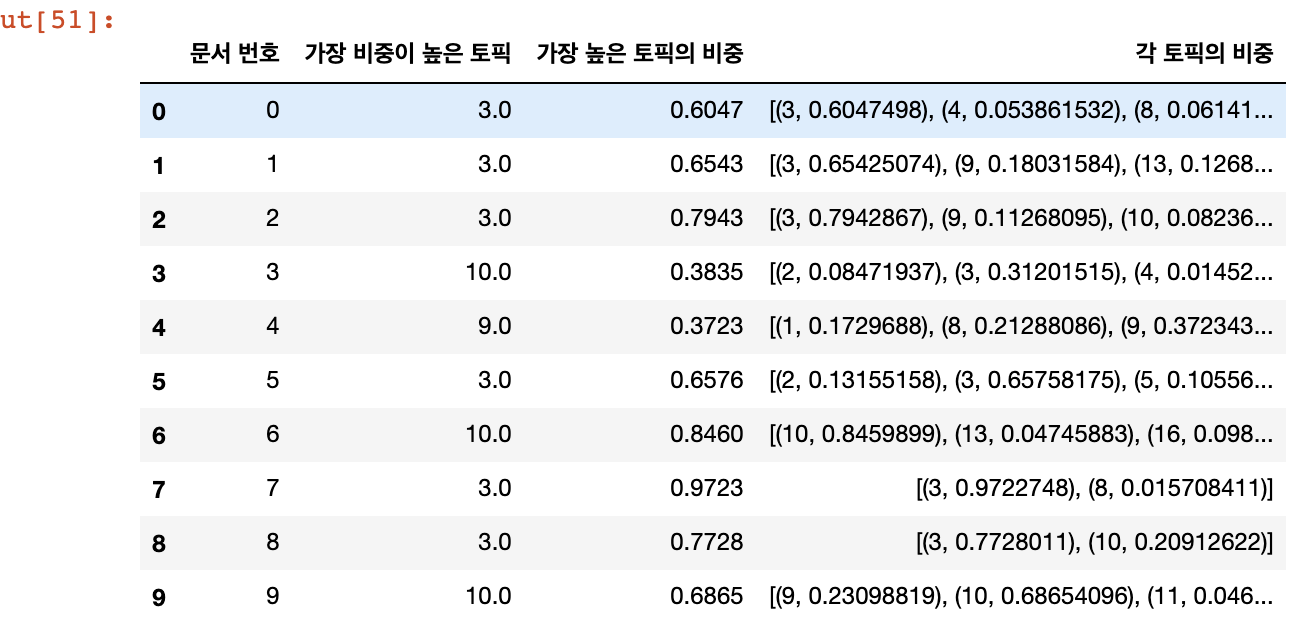
반응형