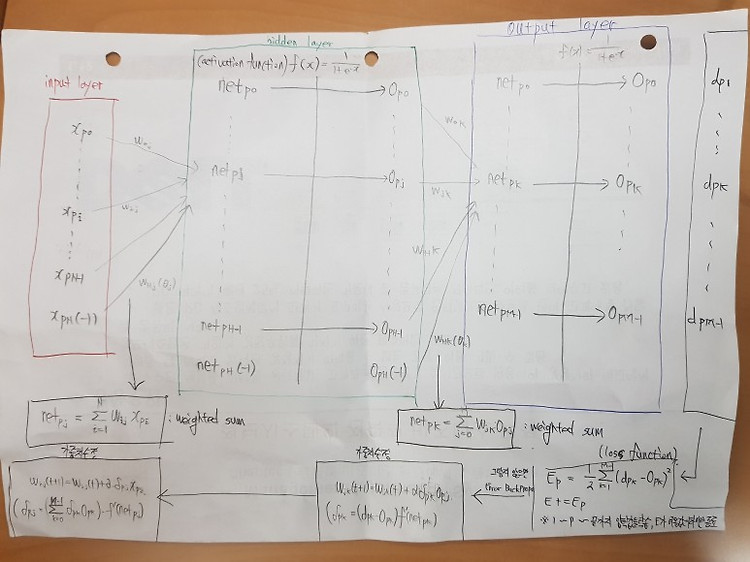
입력데이터의 형태(차원) RNN모델에 시계열 데이터를 입력할 때 입력데이터의 형태는 3차원이 된다. (학습할 데이터의 수, sequence, x값의 개수) 데이터의 수 : 학습할 데이터의 개수 (데이터의 수-sequnce) sequence : 특정값을 구하기 위해 반영할 시간의 길이 x값의 개수 : 사용할 독립변수의 개수 아래의 예시에서 어떻게 이러한 모양이 나오는지 알아 본다. 이해를 돕기위해 데이터의 수는 빨간색, sequence는 초록색, x값의 개수는 파란색으로 표시한다 자전거 이용률 예시 season(계절), holdiay(방학여부), workingday(평일여부)에 따른 자전거 사용횟수(count)가 시계열적으로 나타나있는 데이터가 있다. 데이터의 개수는 총 13128개이다. X의 column..