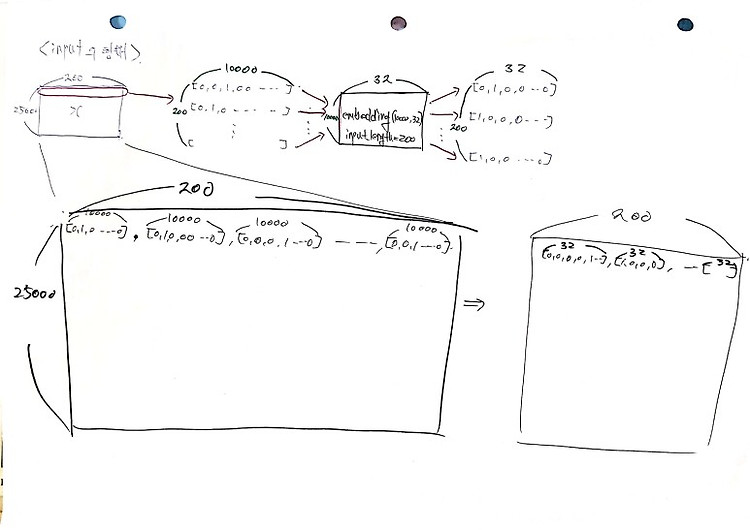
1. 데이터 다운 (1) 데이터 다운 nltk.download() import pandas as pd import urllib.request urllib.request.urlretrieve("https://raw.githubusercontent.com/franciscadias/data/master/abcnews-date-text.csv", filename="abcnews-date-text.csv") data = pd.read_csv('abcnews-date-text.csv', error_bad_lines=False) # 데이터는 총 100만개 print(len(data)) (2) 데이터 상태 보기 # 데이터는 2개의 열로 이루어져 있음 # publish_data : 뉴스가 나온 날짜, headline_t..