
반응형
시리즈
삼성전자 주식데이터를 분석하고 예측한다.
1. 삼성전자 주식 데이터 분석 - 분석하기 => sosoeasy.tistory.com/332
2. 삼성전자 주식 데이터 분석 - 예측하기(MLP 모델)
3. 삼성전자 주식 데이터 분석 - 예측하기(lstm, rnn 모델) => sosoeasy.tistory.com/334
1. 주가데이터 받아오기
#주가 데이터를 받아오기 위한 패키지 설치
!pip install pandas_datareader
!pip install sklearn
2. 패키지 받아오기
datetime : 날짜와 시간을 조작하는 클래스 제공
pandas_datareader : 웹 상의 데이터를 DataFrame 객체로 만드는 기능 제공
pandas : 데이터처리를 위한 라이브러리
numpy : 수치데이터를 다루기위한 라이브러리 (벡터, 행렬 등을 주로 다룸)
tensorflow.compat.v1 tf.disable_v2_behavior() : 2.0이 release 되면서 v1을 사용하고싶을 경우
sklearn.preprocessing : 데이터 전처리 및 분석에 특화 된 라이브러리from datetime import datetime
import pandas_datareader.data as wb
import pandas as pd
import numpy as np
import tensorflow as tf
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import StandardScaler
3. 데이터불러오기
#data loading using yahoo finance api
start = datetime(2000,1,1)
end = datetime(2020,2,10)
#KOSPI의 경우 .KS / KOSDAQ의 경우 .KQ
df = wb.DataReader('005930.KS', 'yahoo', start, end)
4. 데이터 전처리
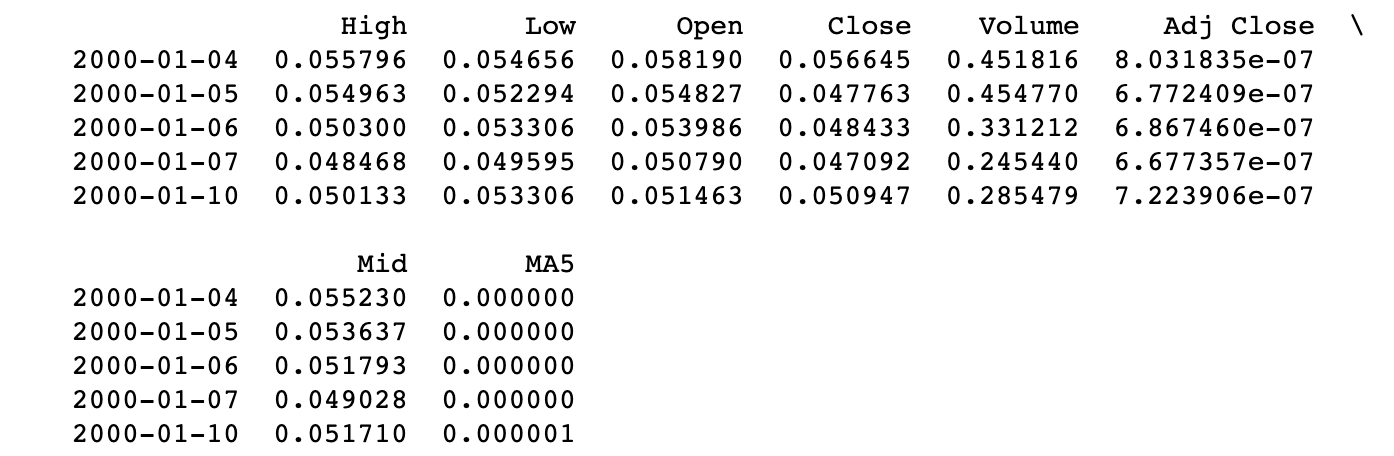
(1) 중간값 att 추가하기
#가격의 중간값 계산하기
high_prices = df['High'].values
low_prices = df['Low'].values
mid_prices = (high_prices+low_prices)/2
mid_prices
#중간 값 요소 추가하기
df['Mid'] = mid_prices
df
(2) 이동평균값 계산하기
#이동평균값 계산하기
ma5 = df['Adj Close'].rolling(window=5).mean()
df['MA5'] = ma5
df = df.fillna(0) #첫 네개의 값은 이동평균값이 없으므로 결측값으로 나오는데, 이를 0으로 채운다
df
(3) 정규화 (Min_max 정규화)
#데이터 스케일링 (preprocessing)
min_max_scaler = MinMaxScaler()
min_max_scaler.fit(df) # min_max scale로 변경
output = min_max_scaler.transform(df) # df형식으로 변경
output = pd.DataFrame(output, columns=df.columns, index=list(df.index.values))
print(output.head())
(4) train, test, validation set 나누기
#train/test size 설정
train_size = int(len(output)*0.6)
test_size = int(len(output)*0.3) +train_size
#train/test/validation set 나누기
train_x = np.array(output[:train_size])
train_y = np.array(output['Close'][:train_size])
test_x =np.array(output[train_size:test_size])
test_y = np.array(output['Close'][train_size:test_size])
validation_x = np.array(output[test_size:])
validation_y = np.array(output['Close'][test_size:])
print(len(train_x))
print(len(test_x))
print(len(validation_x))
print(train_x.shape)3028
1514
505
(3028, 8)
5. tensorflow로 학습하기
(1) 라이브러리 다운로드
from tensorflow.keras import models
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dropout, Dense, Activation
import matplotlib.pyplot as plt
(2) 파라미터, 모델 구조 설정
# 파라미터 설정
learning_rate = 0.01
training_cnt = 500
batch_size = 100
input_size = 8
# 모델 구조 설정
model = Sequential()
#activation [ tahn, sigmoid, relu etc.]
model.add(Dense(input_size, activation='tanh', input_shape=(train_x.shape[1],)))
model.add(Dense(input_size * 3, activation='tanh'))
model.add(Dense(1, activation='tanh'))
#activation [ sgd, rmsprop, adam etc.]
model.compile(optimizer='sgd', loss='mse', metrics=['mae', 'mape','acc'])
model.summary()
(3) 모델 학습, 결과 저장
history = model.fit(train_x, train_y, epochs=training_cnt, batch_size=batch_size, verbose=1)
val_mse, val_mae, val_mape, val_acc = model.evaluate(test_x, test_y, verbose=0)
6. 결과확인
(1) train+test 셋으로 실제값과 예측값 차이 확인
pred = model.predict(test_x)
fig = plt.figure(facecolor='white', figsize=(20, 10))
ax = fig.add_subplot(111)
ax.plot(test_y, label='True')
ax.plot(pred, label='Prediction')
ax.legend()
plt.show()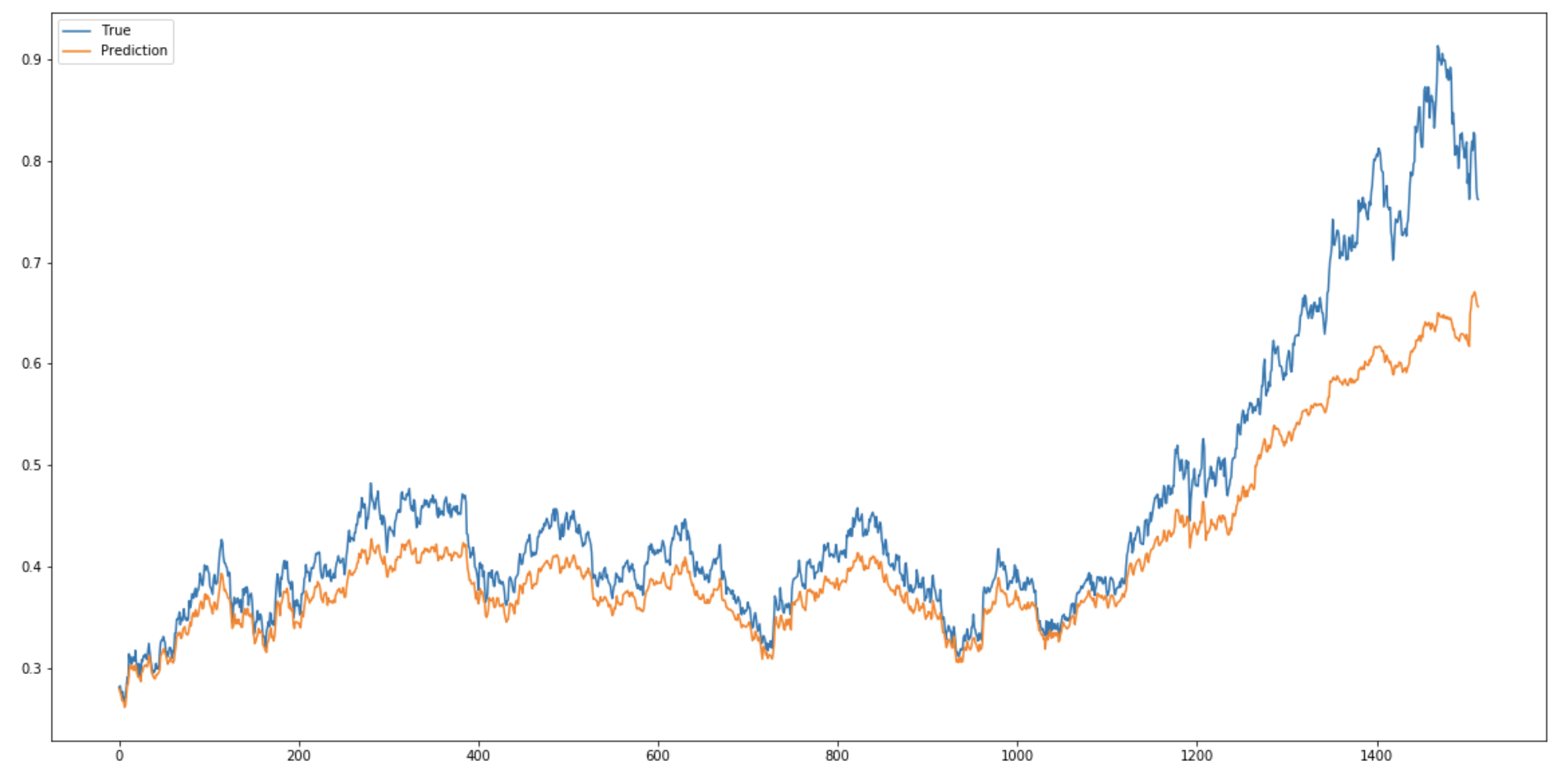
(2) validation 셋으로 실제값과 예측값 차이 확인
#최근 500일 정도의 예측 그래프
pred = model.predict(validation_x)
fig = plt.figure(facecolor='white', figsize=(20, 10))
ax = fig.add_subplot(111)
ax.plot(validation_y, label='True')
ax.plot(pred, label='Prediction')
ax.legend()
plt.show()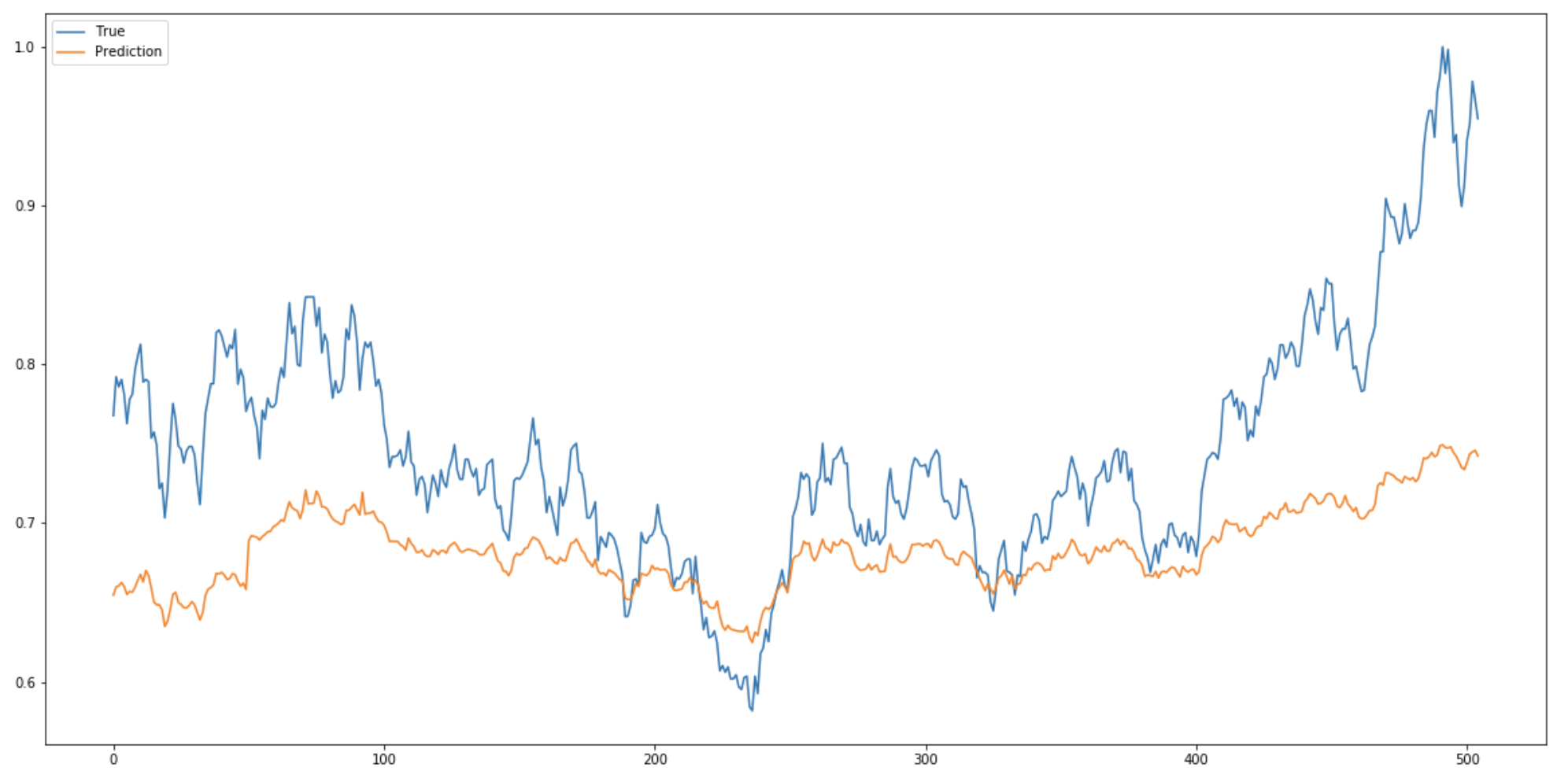
반응형