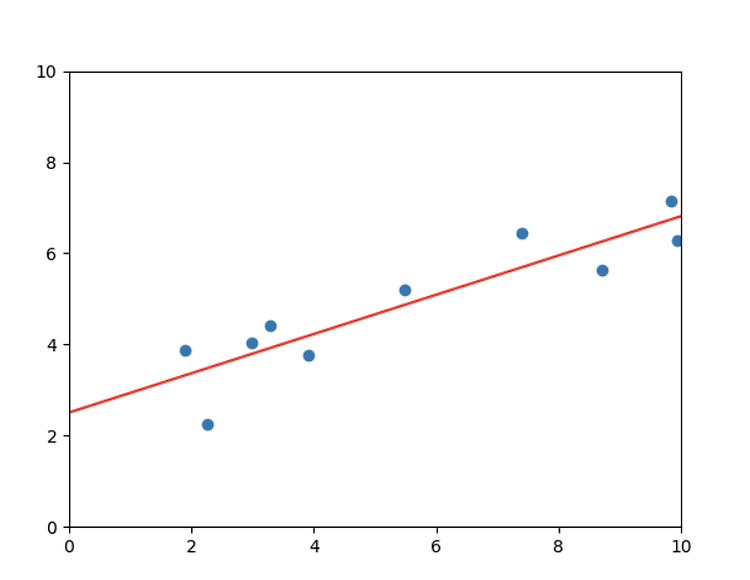
# [백분위수 구하기] from statistics import variance, stdev import numpy as np coffee = np.array([202,177,121,148,89,121,137,158]) #백분위수 cf_quant_20 = np.percentile(coffee, 20) cf_quant_80 = np.percentile(coffee, 80) print("20 Quantiles : ", cf_quant_20 ) print("80 Quantiles : ", cf_quant_80 ) #IQR q75, q25 = np.percentile(coffee, [75, 25]) cf_IQR = q75-q25 print("Inter quartile range:",cf_IQR) 20 Quant..