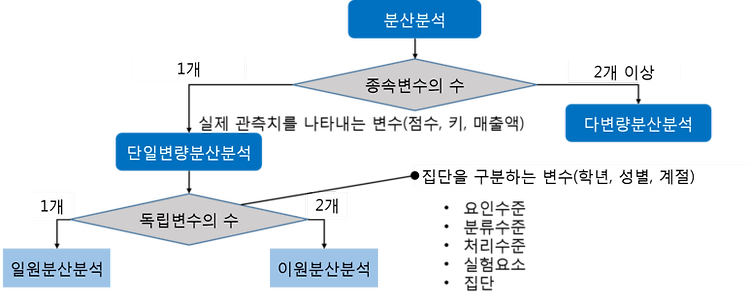
KDD 1. 데이터셋 선택(selection) : 도메인 이해, 목표설정 2. 데이터 전처리(preprocessing) : 잡음, 이상치, 결측치 처리 3. 데이터 변환(transformation) : 변수선택 차원축소 4. 데이터마이닝(data mining) : 분석목적에 맞는 데이터마이닝기법 선택, 적절한 알고리즘 적용 5. 해석과 평가(interpretation, evaluation) : 일치성확인 및 평가 CRISP-DM 1. 업무이해 : 비즈니스 관점에서 프로젝트의 목적과 요구사항을 이해, 데이터 분석을 위한 문제정의 - 업무목적 파악, 상황파악, 목표설정, 계획수립 2. 데이터 이해 : 분석을 위한 데이터를 수집하고 데이터 속성을 이해, 인사이트 발견 - 초기데이터 수집, 데이터 기술 분석, ..