
반응형
1. 파일 읽기
import numpy as np
import pandas as pd
from pandas import ExcelFile
import tensorflow as tf
from tensorflow.keras import layers #모듈(변수나 함수를 포함)만 불러오기
from sklearn.preprocessing import StandardScaler, MinMaxScaler #표준 정규화, 최대-최소 정규화
#df = pd.read_excel('File.xlsx', sheetname='Sheet1') #sheet명도 지정할 수 있음
df = pd.read_excel('Real estate valuation data set.xlsx')
print(df.columns)*print() :
Index(['No', 'X1 transaction date', 'X2 house age',
'X3 distance to the nearest MRT station',
'X4 number of convenience stores', 'X5 latitude', 'X6 longitude',
'Y house price of unit area'],
dtype='object')
2. 데이터 추출
# df에서 모든행, 0~6열만 split (pandas의 data를 number index로 slicing 하는 방법)
X = df.iloc[:,1:7]
# df에서 모든행, 6열만 split2.
y = df.iloc[:,7]
3. 정규화
# 모든 컬럼을 유사하고 적절한 구간으로 정규화 하기
# StandardScaler() #각 컬럼들에 min-max scaling 또는 z-score normalization 적용
scaler = MinMaxScaler()
X_norm = scaler.fit_transform(X)
4. 데이터 set 분류
# X는 정규화하는 과정에서 numpy Type으로 바뀌지만
y는 그렇지 않기 때문에 아래와 같이 numpy타입으로 바꿔준다.
numpY = np.empty((414,1))
for i in range(414):
numpY[i]=y[i]
# training set과 test set으로 나누기
X_train, y_train = X_norm[0:300], numpY[0:300]
X_test, y_test = X_norm[300:414], numpY[300:414]
5. 모델링
# 모델 구조 정의하기
model = tf.keras.Sequential()
#입력 8개로부터 전달받는 12개 노드의 layer 생성
model.add(layers.Dense(12, input_shape=(6,)))
model.add(layers.Activation('relu'))
model.add(layers.Dense(12))
model.add(layers.Activation('relu'))
model.add(layers.Dense(12))
model.add(layers.Activation('relu'))
#회귀모형(regression) 구축을 위해서 linear 활성함수 사용
model.add(layers.Dense(1))
model.add(layers.Activation('linear'))
# 모델 구축하기
model.compile(
loss='mse', # mean_squared_error(평균제곱오차)의 alias
optimizer='adam', # 최적화 기법 중 하나
metrics=['mae']) # 실험 후 관찰하고 싶은 metric 들을 나열함.
6. 훈련
'''
10개에 한 번씩 업데이터 실행
0:미출력, 1:진행상황출력, 2:에포크당 출력
'''
hist = model.fit(
X_train, y_train,
batch_size=10,
epochs=100,
validation_split=0.2,
callbacks=[tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)],
verbose=2)
# 테스트 데이터 입력
scores = model.evaluate(X_test, y_test)
print('test_loss: ', scores[0])
print('test_mae: ', scores[1])
# 모델 저장
model.save("dnn_estate.h5")
7. 테스트 데이터 loss, mae확인
# 관찰된 metric 값들을 확인함
for i in range(len(scores)):
print("%s: %.2f" % (model.metrics_names[i], scores[i]))loss: 66.44
mae: 6.34
8. 학습 그래프 측정
import matplotlib.pyplot as plt
fig, loss_ax = plt.subplots(figsize=(15, 5))
acc_ax = loss_ax.twinx()
loss_ax.plot(hist.history['loss'], 'y', label='train loss') # 훈련데이터의 loss (즉, mse)
loss_ax.plot(hist.history['val_loss'], 'r', label='val loss') # 검증데이터의 loss (즉, mse)
acc_ax.plot(hist.history['mae'], 'b', label='train mae') # 훈련데이터의 mae
acc_ax.plot(hist.history['val_mae'], 'g', label='val mae') # 검증데이터의 mae
loss_ax.set_xlabel('epoch')
loss_ax.set_ylabel('loss')
acc_ax.set_ylabel('mean_absolute_error')
loss_ax.legend(loc='upper left')
acc_ax.legend(loc='lower left')
plt.show()
9. 시각화
import matplotlib.pyplot as plt
# test data에 대한 예측값
y_pred = model.predict(X_test)
# 그림 가로, 세로 크기
plt.figure(figsize=(10,10))
#test data의 실제 y값과 예측 y값을 입력 => y=x 그래프와 가까울수록 정확
plt.scatter(y_test, y_pred, label="house price per unit", s=3)
plt.title('Comparison b/w Actual and Predicted Values')
# X축 이름
plt.xlabel('y_actual')
# Y축 이름
plt.ylabel('y_predicted')
# 범례표시
plt.legend()
# X축 표시 범위, Y축 표시 범위
plt.xlim((0,100))
plt.ylim((0,100))
plt.show()
10. 모델 불러오기
# 필요모듈
# from numpy import loadtxt
from tensorflow.python.keras.models import load_model
# 모델 불러오기
loaded_model = load_model("dnn_estate.h5")
11. 파라미터 개수
model.summary()
score = model.evaluate(X_test, y_test)
print('test_loss: ', score[0])
print('test_mse: ', score[1])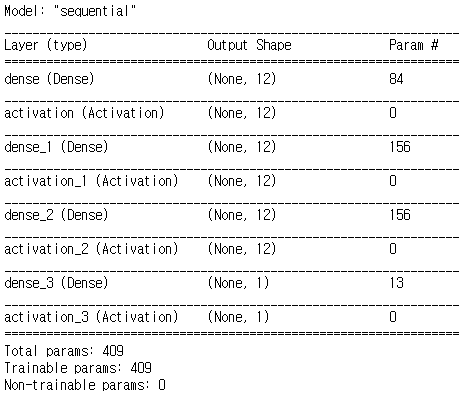
<<파라미터계산>>
1. input layer:
84=(6+1(bias))*12
2. 첫번째 hidden layer:
156=(12+1(bias))*12
3. 두번째 hidden layer:
156=(12+1(bias))*12
3. output layer:
13=(12+1(bias))*1
12. 한값만 에측해보기
# 한값만 예측
# 정규화된 X 값
y_pred = model.predict(X_norm[[300]])
print('y_pred = ', y_pred)
print('y_test = ', y[300])
# 정규화 되지 않은 새로운 X값
X_new = [2013.08300, 2.50000, 156.24420, 4.00000, 24.96696, 121.53992]
# X를 정규화
X_new_norm = scaler.transform([X_new])
y_pred = model.predict(np.array(X_new_norm,))
print("y_pred = ", y_pred)
print("y_actual = ", y_test[0])더보기
y_pred = [[43.98163]]
y_test = 36.9
y_pred = [[43.979675]]
y_actual = [36.9]
반응형