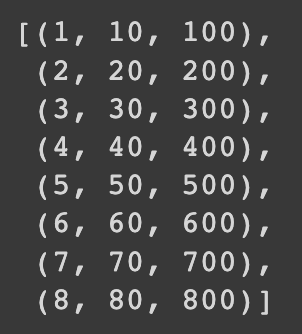
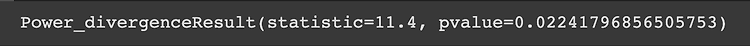파이썬 zip함수 여러 iterable한 자료형을 순서대로 묶어준다 예시 1 a=[1,2,3,4,5,6,7,8,9] b=[10,20,30,40,50,60,70,80,90] c=[100,200,300,400,500,600,700,800,900] list(zip(a,b,c)) 예시 2 : 묶을 데이터의 길이가 다르면 같은 거 까지만 묵어준다 a=[1,2,3,4,5,6,7,8,9] b=[10,20,30,40,50,60,70,80,90,10,20] c=[100,200,300,400,500,600,700,800,900,100,200] list(zip(a,b,c)) 예시 3 : 자료형이 달라도 묶인다 a=[1,2,3,4,5,6,7,8,9] b={10,20,30,40,50,60,70,80,90,10,20} c=(10..