
여기에 아래 링크에 다시 정리했습니다!
데이터 전처리 관련 함수
* 넘파이는 np, 판다스는 pd import numpy as np import pandas as pd 결측치 함수 설명 리턴값 비고 np.isnan(data) data값이 nana값이면 True를 반환 True or False sosoeasy.tistory.com/188 데이터변환 (data..
sosoeasy.tistory.com
0. 파일 불러오기
csv=pd.read_csv("NYPD_Complaint_Data_Current_YTD.csv")
1. 데이터 추가하기
df=pd.DataFrame(columns=["season","time","crime_code","street"])
# ignore_index=True를 사용해야 인덱스를 적지않아도 됨.
df=df.append({"season":1,"time":2,"crime_code":3,"street":4},ignore_index=True)
print(df)
2. 데이터 프레임 생성
(1) 행단위 입력
df=pd.DataFrame(data=[[1,2],[3,4]] , columns=["a","b"])
df
(2) 열단위 입력
df2=pd.DataFrame({"a":[1,2],"b":[3,4]})
df2
3. 행단위 읽기
# df라는 데이터프레임을 인덱스 기준으로 읽기
df.loc[i]
4. 속성 이름확인, 추가
(1) 속성이름 확인
import pandas as pd
#파일의 첫번째 행(att)을 표시
print(csv.columns)Index(['CMPLNT_FR_DT', 'CMPLNT_FR_TM', 'KY_CD', 'OFNS_DESC', 'BORO_NM',
'ADDR_PCT_CD', 'PREM_TYP_DESC'],
dtype='object')
(2) 속성이름 설정
dataFrame.columns = ["속성1이름","속성2이름"]column수만큼 리스트의 요소를 구성하고 대입
5. 상위 5개 값 보기
df.head()
6. 하위 5개값 보기
df.tail()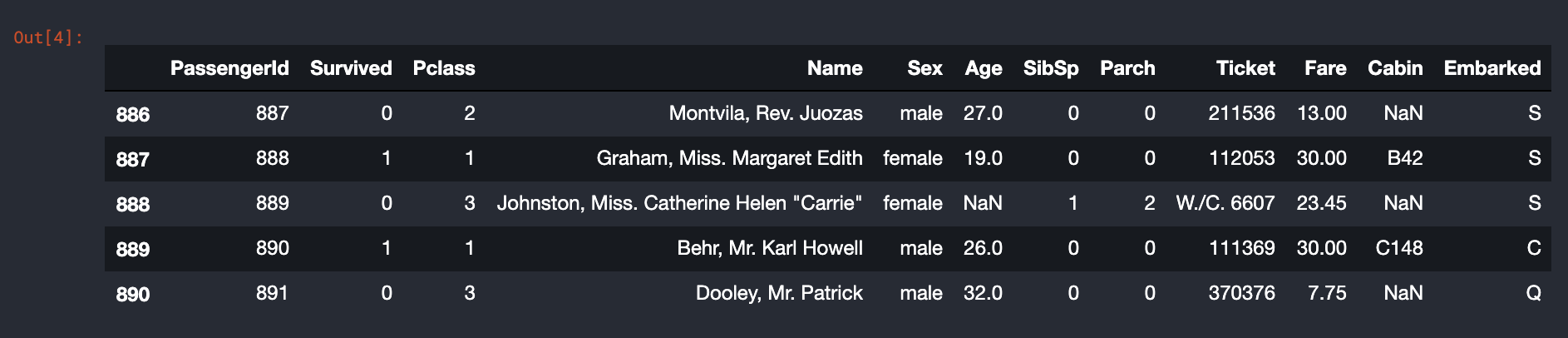
7. 데이터 타입 확인 및 수정
1. 데이터입 확인하기
df.dtypes

2. 데이터타입 바꾸기
df=df.astype({"colName":"type"})
8. 데이터 타입 + 빈칸이 아닌 것의 개수 확인
df.info()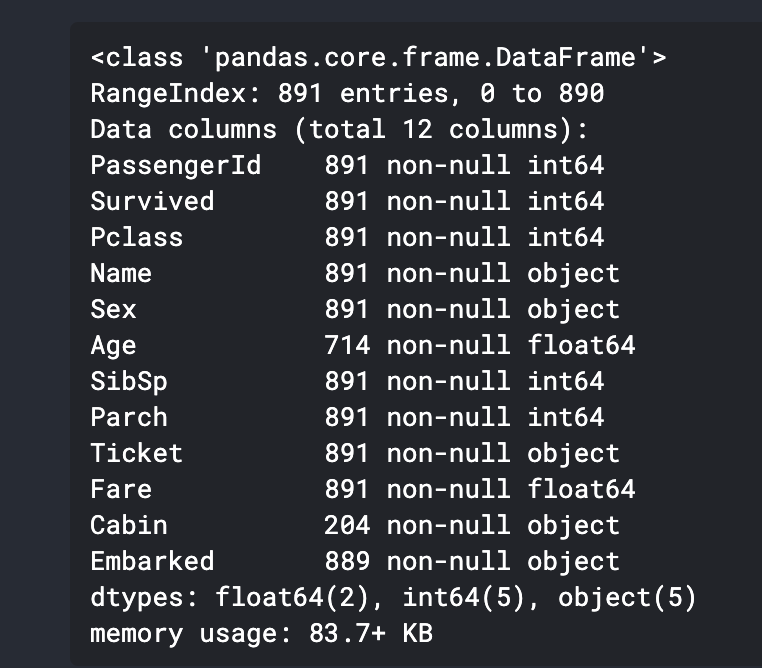
9. 통계적인 부분 확인
# all이 있으면 이산형 att도 다 보여줌(all 파라미터가 없으면 연속형만 보여줌)
csv.describe(include='all')
10. 두 데이터 프레임을 합치는 법.
(1) 세로로 붙이기
a=pd.DataFrame({"a":[1,2],"b":[3,4]})
display(a)
b=pd.DataFrame({"a":[3,4],"b":[5,6]})
display(b)
pd.concat((a,b))
(2) 가로로 붙이기
newDF = pd.concat([A,B], axis=1)
#A,B,C를 가로로 붙임. row의 수는 같아야함
11. 특정 att에서 도매인별 개수를 카운트하는 함수
print(train['Survived'].value_counts())print(train.Survived.value_counts())
*이를 그림으로 그리는 코드
fig = plt.figure(figsize=(10,2)) #그림판의 크기 정함
sns.countplot(y='Survived', data=train) #seaborn의 카운트플룻을 그리라는것

12. 비어있는 값 확인
(1) 결측치 전체 확인
# 결측치이면 True, 그렇지않으면 False
data.isnull()
(2) 비어있는 값의 합
비어있는 값이 att를 기준으로 몇개씩 있는지 확인할 수 있다.
data.isnull().sum() #비어 있는 값들을 체크해 본다.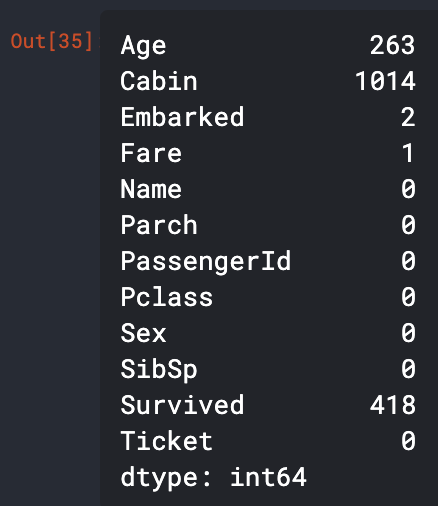
data.isnull().sum().sum() #모든특성에서 결측치가 몇개인지 셀때는 .sum()을 뒤에 떠 붙여준다
(3) att의 도메인중 비어있는 값이 하나라도 있는지 확인
data.att.isnull().any()True or False
13. groupby로 묶기
(1) 2개의 group로 group by
gropuby([x,y])를 하면 x를 기준으로 y의 도메인별 개수를 보여준다.
train.groupby(['Survived','Pclass'])['Survived'].count()Survived Pclass
0 1 80
2 97
3 372
1 1 136
2 87
3 119
Name: Survived, dtype: int64
train.groupby(['Pclass','Survived'])['Survived'].count()Pclass Survived
1 0 80
1 136
2 0 97
1 87
3 0 372
1 119
Name: Survived, dtype: int64
gropuby([x,y])[z].count()에서 z는 무슨역할을 하는지잘 모르겠다 다르게 써도 같은 결과가 나온다..
(2) agg함수이용하면?
temp.groupby('Initial').agg({'Age': ['mean', 'count']}) #이니셜 별 평균 연령 체크
14. index 설정 및 초기화
(1) 설정
dataframe.set_index('데이터프레임의 인덱스로 설정할 att의 이름', inplace=True)
<example>
raw_all = pd.read_csv(location)
raw_all
raw_all.set_index('DateTime', inplace=True)
raw_all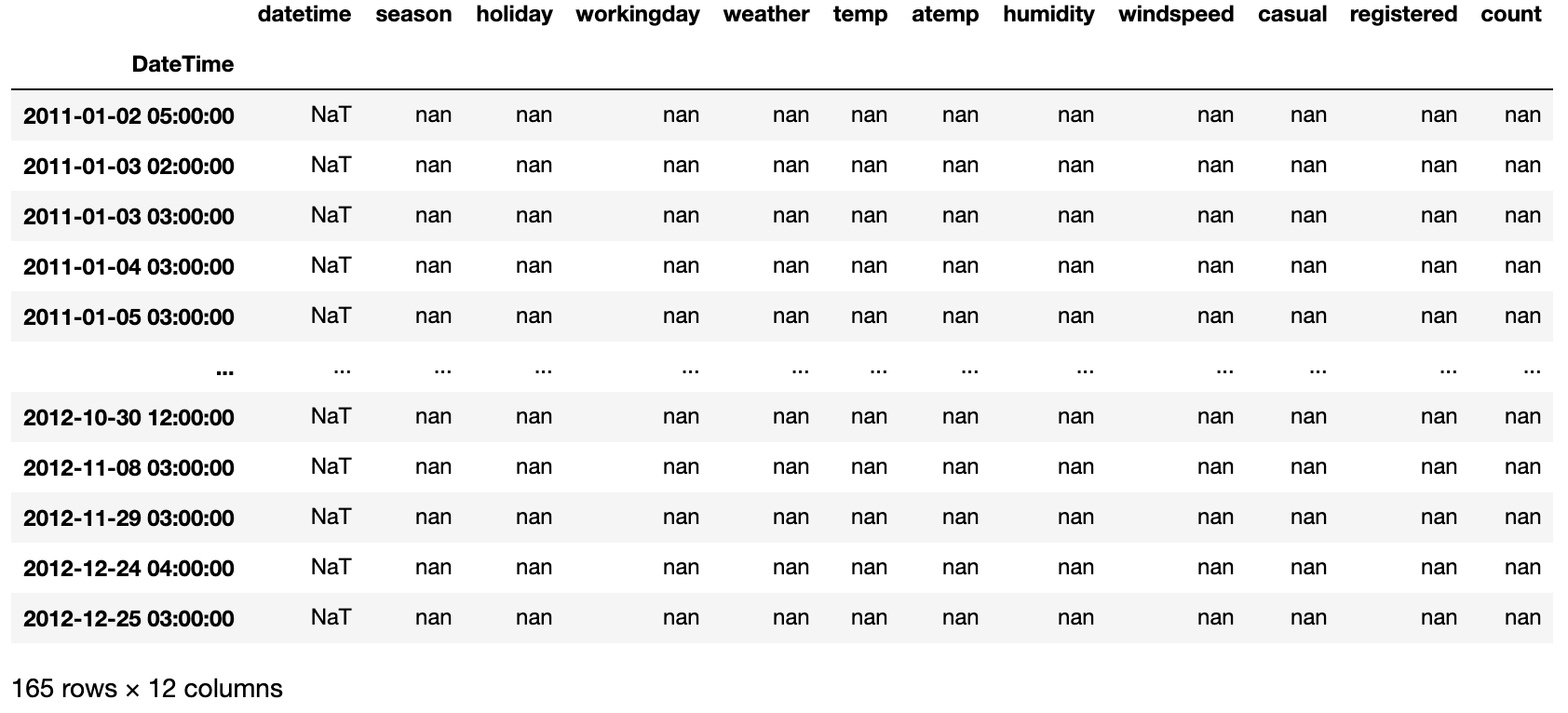
(2) 초기화
raw_all.reset_index(drop=False, inplace=True)
raw_all
15. 데이터 column단위로 보기(참조)
<example>
print(raw_all.dtypes)
(1) series 타입으로 보기
print(type(raw_all.weather))
raw_all.weather
print(type(raw_all['weather']))
raw_all['weather']
(2) dataFrame 타입으로 보기
print(type(raw_all[['weather']]))
raw_all['weather']
16. dummy데이터 만들기
raw_all['Quater']
pd.get_dummies(raw_all['Quater']) #데이터를 더미로 만들어줌(원핫코딩)
17. 특정 column만 제외하고 정의하기
dataFrame에서 특정 column만을 제외하고싶으면 아래와 같이 코드를 구현하면 된다.
raw_all.loc[:, [col for col in raw_all.columns if col != {제외할 att}]]
<example>
raw_all
raw_all.loc[:, [col for col in raw_all.columns if col != 'temp_group']]
18. 특정 att의 도메인별 개수확인
<example>
raw_fe['weather']
raw_fe['weather'].value_counts()
19. 정렬
dataframe.sort_values(by="정렬기준이 될 변수이름", ascending=True)
# ascending:오름차순 여부