
반응형
페이스북에서 개발한 fbprophet을 이용하여 시계열 분석을 수행한다.
1. 필요 라이브러리 임포트
import timeit
start = timeit.default_timer()
from fbprophet import Prophet
from fbprophet.plot import plot_plotly, plot_components_plotly
from fbprophet.plot import add_changepoints_to_plot
2. 데이터 전처리
(1) 데이터 합치기
# Rearrange of Data
Y_train_feR_prophet = Y_train_feR.reset_index()
Y_train_feR_prophet.columns = ['ds', 'y']
YX_train_prophet = pd.concat([Y_train_feR_prophet,
X_train_feRSM.reset_index().iloc[:,1:]],
axis=1)
(2) 값 바운더리 정하기
# Applying Prophet Model
### saturating ###
saturating = 'logistic'
if saturating == 'logistic':
YX_train_prophet['cap'] = 900
YX_train_prophet['floor'] = 0
##################
(3) 휴일 추가
### holiday ###
newyear = pd.DataFrame({'holiday': 'newyear',
'ds': pd.to_datetime(['2011-01-01', '2012-01-01']),
'lower_window': 0, # 이전날짜 포함범위
'upper_window': 1}) # 이후날짜 포함범위
christmas = pd.DataFrame({'holiday': 'christmas',
'ds': pd.to_datetime(['2011-12-25', '2012-12-25']), # 미래 시점도 포함
'lower_window': 0, # 이전날짜 포함범위
'upper_window': 1}) # 이후날짜 포함범위
holidays = pd.concat([newyear, christmas])
################
3. 모델링 및 학습
(1) 파라미터 지정
fit_reg1_feRSM_prophet = Prophet(growth=saturating,
# Trend
changepoints=None, # CP가 발생하는 시점들의 list ['2012-01-01']
n_changepoints=25, # CP의 수
changepoint_range=0.9, # CP의 기존 데이터 수 대비 최대 비율
changepoint_prior_scale=0.5, # CP 추정 민감도로 높을수록 민감
# Seasonality
seasonality_mode='additive', # 계절성 모델: 'additive' or 'multiplicative'
seasonality_prior_scale=20.0, # 계절성 추정 민감도로 높을수록 민감
yearly_seasonality='auto', # 연계절성
weekly_seasonality='auto', # 주계절성
daily_seasonality='auto', #일계절성
# Holiday
holidays=holidays, # 휴일 또는 이벤트 시점 dataframe
holidays_prior_scale=5.0, # 휴일 추정 민감도로 높을수록 민감 (이전결과참고반영)
# Others
interval_width=0.8, # 추세 예측 정확도 구간범위
mcmc_samples=0) # 계절성 예측 정확도 제어
(2) 필요한 내용을 추가로 넣을 수 있다.
### holiday 추가###
fit_reg1_feRSM_prophet.add_country_holidays(country_name='US')
###############
### monthly seasonality ###
# 계절성을 추가할 수 있다. 새로운 이름과 원래 주기(여기서는 H)를 적절히 바꿔서(아래 예시는 월이므로 24*7*4) 추가한다.
# fit_reg1_feRSM_prophet.add_seasonality(name='monthly', period=24*7*4, fourier_order=1)
###########################
### extra feature ###
# 설명변수 추가
target_name = X_train_feRSM.columns[:5]
for col in target_name:
fit_reg1_feRSM_prophet.add_regressor(col)
#####################
(3) 학습
fit_reg1_feRSM_prophet = fit_reg1_feRSM_prophet.fit(YX_train_prophet)
4. 예측
(1) 예측
forecast = fit_reg1_feRSM_prophet.make_future_dataframe(freq='H',
periods=Y_test_feR.shape[0])
### saturating ###
if saturating == 'logistic':
forecast['cap'] = 700
forecast['floor'] = 0
##################
### extra feature ###
forecast = pd.concat([forecast,
pd.concat([X_train_feRSM[target_name],
X_test_feRSM[target_name]], axis=0).reset_index().iloc[:,1:]],
axis=1)
#####################
pred_reg1_feRSM_prophet = fit_reg1_feRSM_prophet.predict(forecast)
pred_tr_reg1_feRSM_prophet = np.ravel(pred_reg1_feRSM_prophet.loc[:Y_train_feR.shape[0]-1, ['yhat']])
pred_te_reg1_feRSM_prophet = np.ravel(pred_reg1_feRSM_prophet.loc[Y_train_feR.shape[0]:, ['yhat']])
(2) 예측값 시각화
# Result
display(pred_reg1_feRSM_prophet[['ds', 'yhat', 'yhat_lower', 'yhat_upper']])
fig = fit_reg1_feRSM_prophet.plot(pred_reg1_feRSM_prophet)
add_changepoints_to_plot(fig.gca(), fit_reg1_feRSM_prophet, pred_reg1_feRSM_prophet)
plt.xticks(rotation=90)
plt.show()
fig = fit_reg1_feRSM_prophet.plot_components(pred_reg1_feRSM_prophet)
ax = fig.get_axes()
for i in range(len(ax)):
ax[i].tick_params(axis="x", labelsize=15, rotation=90)
plt.show()


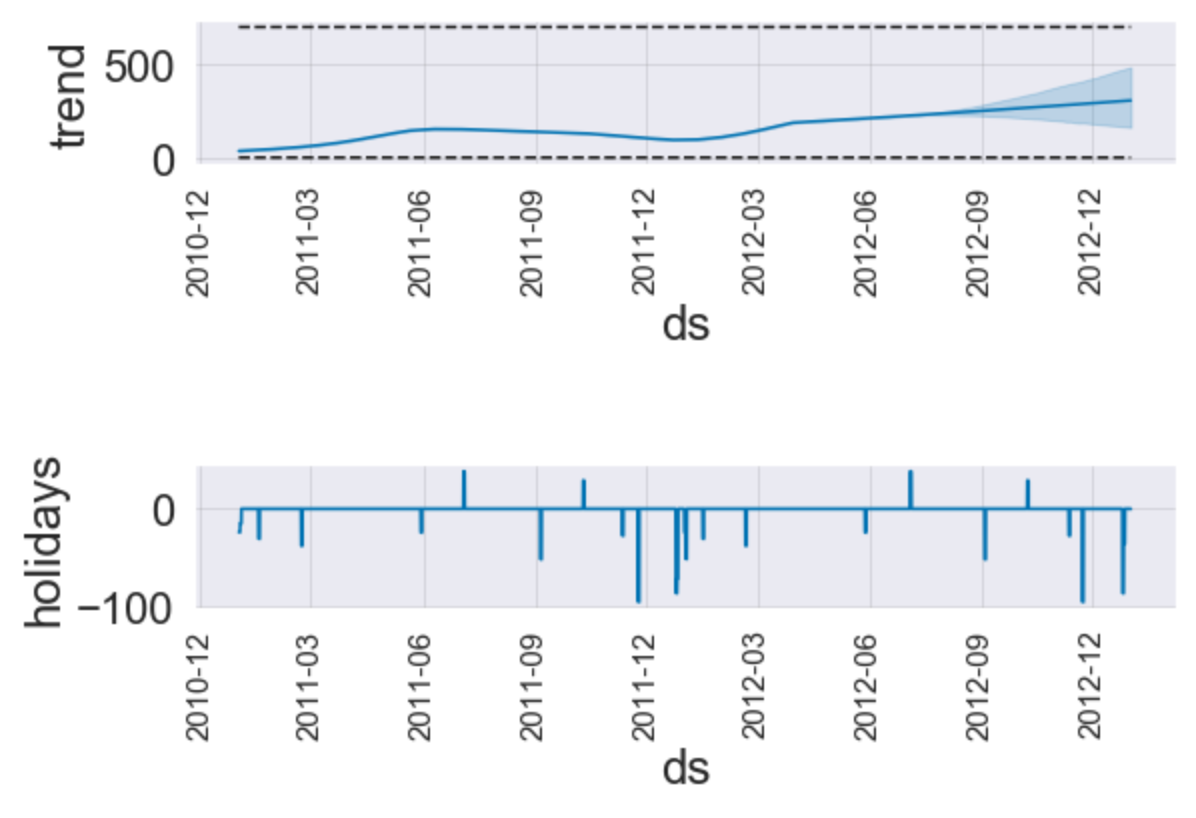
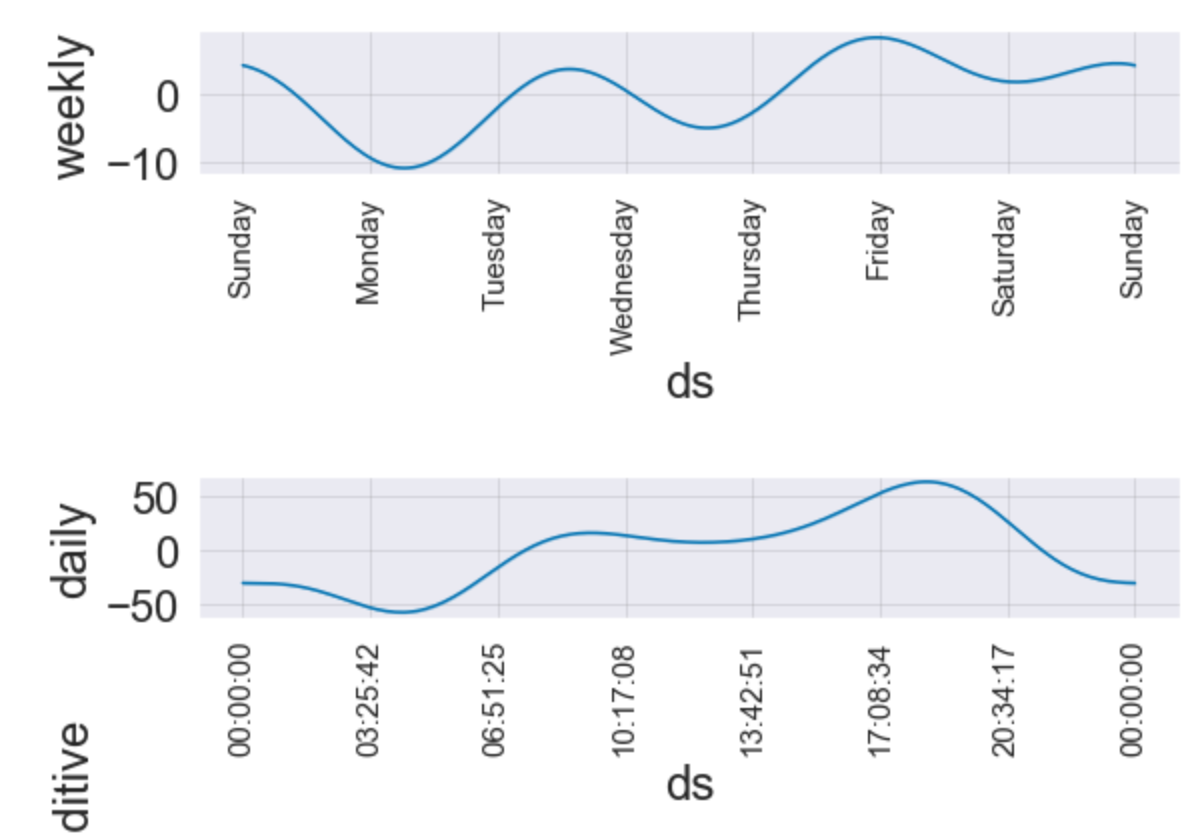
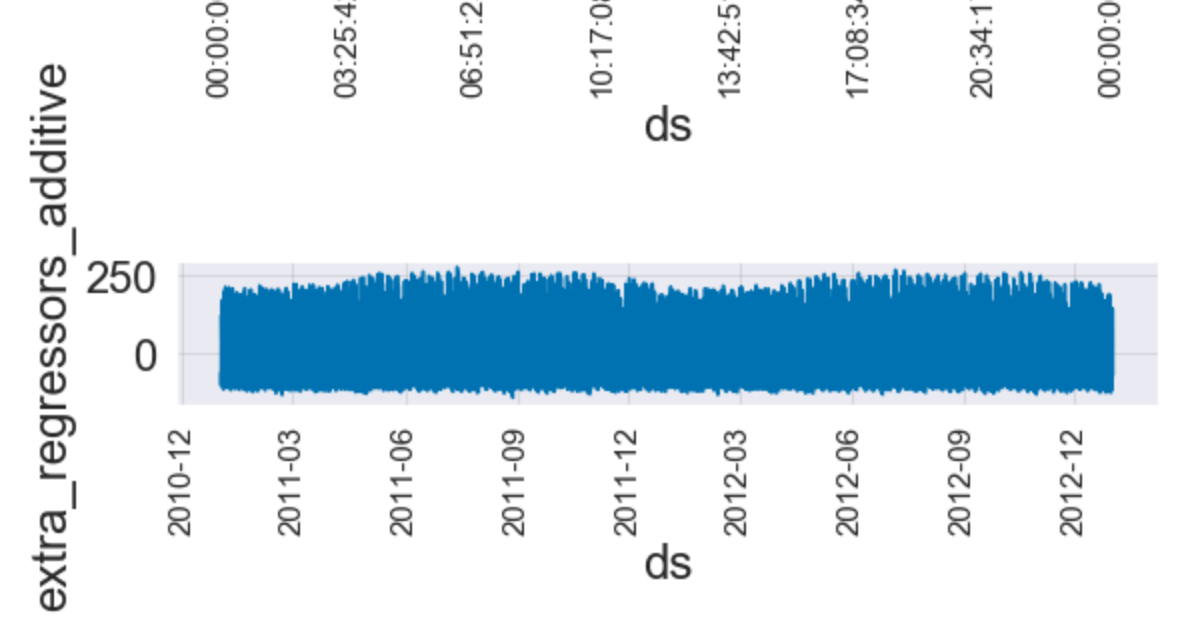
5. 평가
## using plotly
# display(plot_plotly(fit_reg1_feRSM_prophet, pred_reg1_feRSM_prophet))
# display(plot_components_plotly(fit_reg1_feRSM_prophet, pred_reg1_feRSM_prophet))
# Evaluation
Score_reg1_feRSM_prophet, \
Resid_tr_reg1_feRSM_prophet, \
Resid_te_reg1_feRSM_prophet = evaluation_trte(Y_train_feR,
pred_tr_reg1_feRSM_prophet,
Y_test_feR,
pred_te_reg1_feRSM_prophet,
graph_on=True)
display(Score_reg1_feRSM_prophet)


6. 잔차분석
# Error Analysis
error_analysis(Resid_tr_reg1_feRSM_prophet, ['Error'], X_train_feRSM, graph_on=True)
stop = timeit.default_timer()
print('Time: ', stop - start)
*출처 : 패스트캠퍼스 "파이썬을 활용한 시계열 데이터분석 A-Z"
반응형