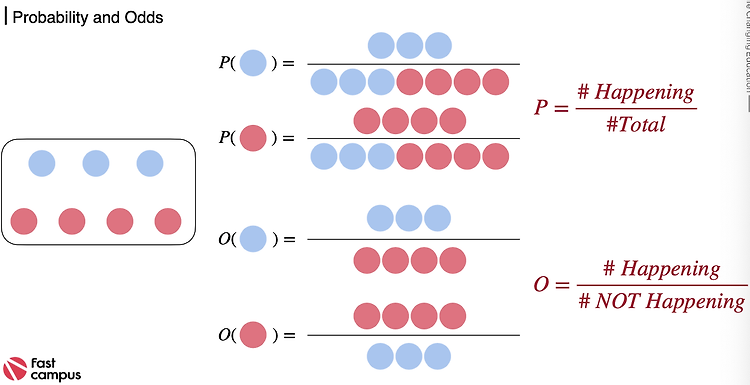
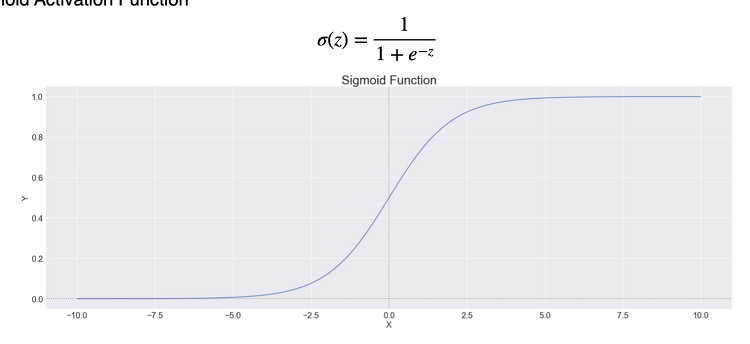
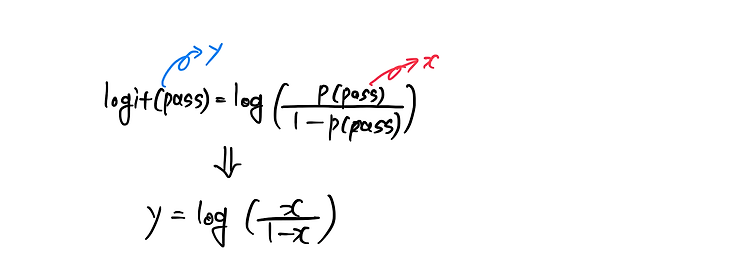1. 정보량(1) 확률과 반비례 관계발생할 확률이 낮은 사건이 발생한다는 사실을 알때 정보의 양은 커진다. 그러니까 확률과 정보의 양은 반비례하다.(2) 숫자 예시1~100까지 숫자중 정답인 숫자를 맞춰야 하는 문제가 있다고 가정하자.정답이 1~10까지 중에 있다는 정보는 확률이 10/100 => 정보의 양은 10정답이 1~20까지 중에 있다는 정보는 확률이 20/100 -=> 정보의 양은 5..정답이 1~100까지 중에 있다는 정보는 확률이 100/100 => 정보의 양은 1 (3) 로그취하기이때 동전 던지기로 정보의 양은 표현하면동전 하나를 던졌을때 하나가 앞면이 나올 확률은 1/2 => 정보의 양은 2동전 두개를 던졌을 때 두개가 앞면이 나올 확률은 1/2^2 => 정보의 양은 2^2..동전 n개를..