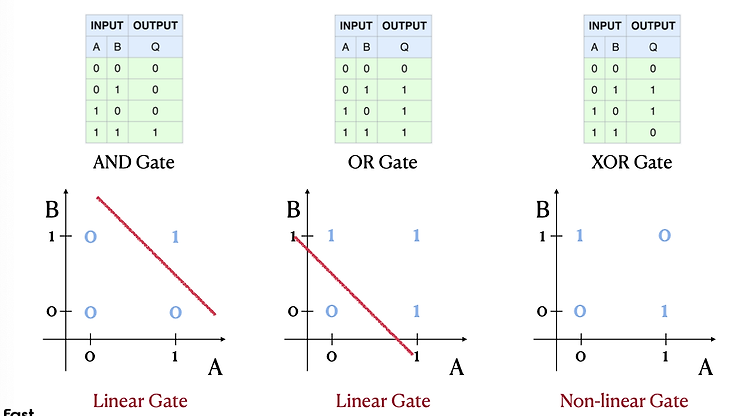
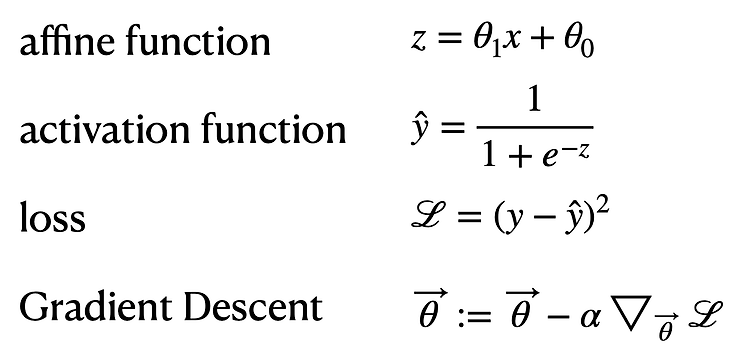로지스틱 회귀에서는 loss를 MSE를 쓰지않고 BCE(Binary Cross Entropy)를 쓴다. 그렇다면 왜 로지스틱 회구에서는 BCE loss를 쓰는지 알아본다.1. MSE위와같이 loss를 MSE를 사용하고 gradient descent meathod를 이용하여 최적값을 찾으려고 한다.이때 loss function은 아래와 같다. 이때 문제는 바로 좌우측에 평평한 부분이다. 모양이 너무 평평해서 기울기를 따라 내려가야 하는데, 기울기가 거의 없어서 거의 내려가질 않는 것이다. 이를 convex하지 않다, 즉 볼록하지 않다고 한다.이를 빨간색으로 표시하면 아래와 같다. (학습이 잘되는 부분은 초록색으로 표시) 2. BCE이번엔 위와같이 Loss를 bce를 사용했을때를 본다.bce를 사용하면 Lo..