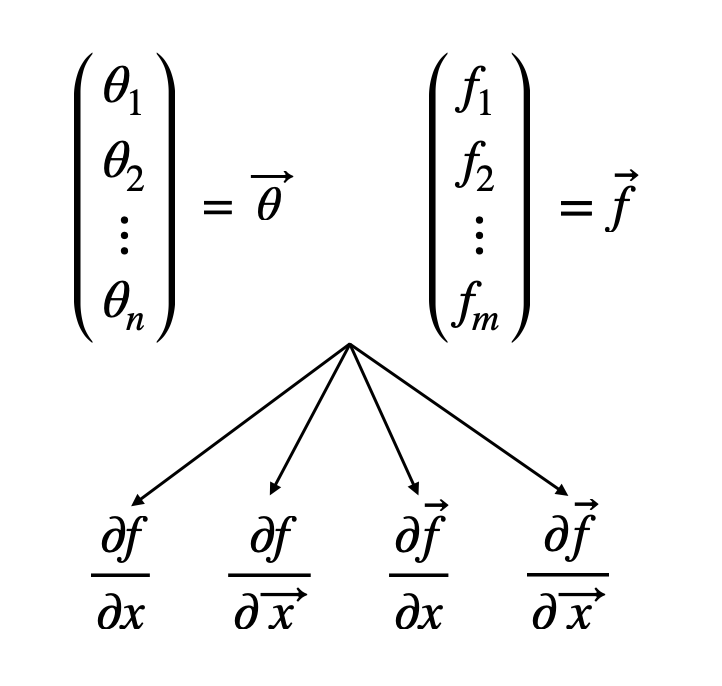
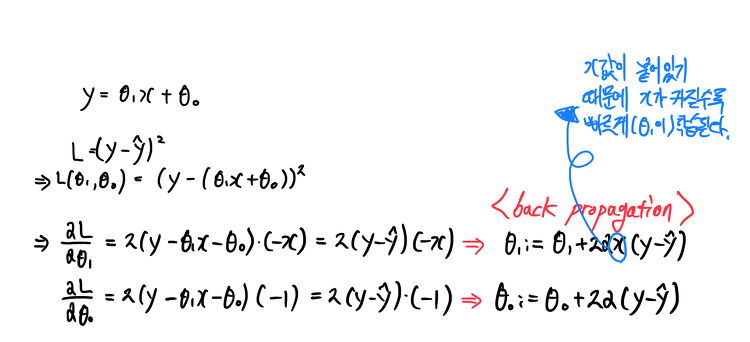데이터 생성기
y=ax+b 로 선형회귀분석을 하기위해 데이터를 생성하는 클래스. (1) 소스코드 import numpy as np import matplotlib.pyplot as plt class dataset_generator: def __init__(self,feature_dim=1,n_sample=100,noise=0): self._feature_dim=feature_dim self._n_sample=n_sample self._noise=noise self._coefficient=None self._init_set_coefficient() # 초기 기울기값 설정, 마지막값은 bias (기울기는 1로 초기화, bias는 0으로 초기화) def _init_set_coefficient(self): self._coef..